LHC Databases on the Grid: Achievements and Open Issues
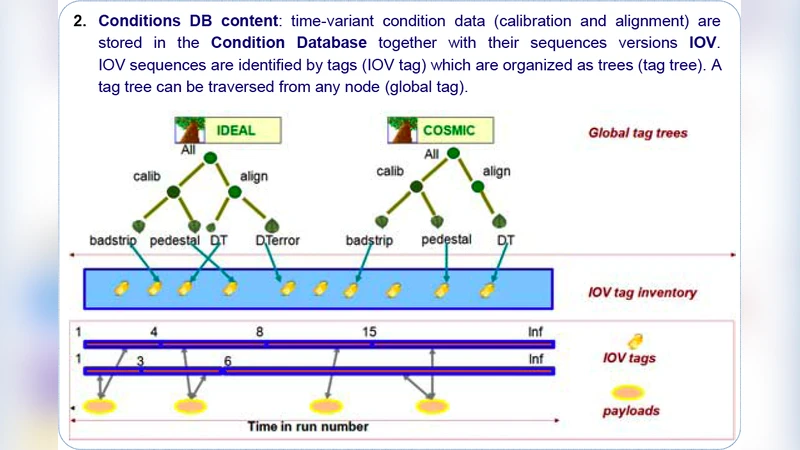
To extract physics results from the recorded data, the LHC experiments are using Grid computing infrastructure. The event data processing on the Grid requires scalable access to non-event data (detector conditions, calibrations, etc.) stored in relational databases. The database-resident data are critical for the event data reconstruction processing steps and often required for physics analysis. This paper reviews LHC experience with database technologies for the Grid computing. List of topics includes: database integration with Grid computing models of the LHC experiments; choice of database technologies; examples of database interfaces; distributed database applications (data complexity, update frequency, data volumes and access patterns); scalability of database access in the Grid computing environment of the LHC experiments. The review describes areas in which substantial progress was made and remaining open issues.
💡 Research Summary
The paper provides a comprehensive review of how the four LHC experiments (ATLAS, CMS, ALICE, and LHCb) manage non‑event data—conditions, calibrations, alignment constants, and other metadata—on the worldwide Grid computing infrastructure. It begins by emphasizing that accurate physics results depend not only on the massive streams of raw event data but also on timely, consistent access to these auxiliary data sets, which are stored in relational database management systems (RDBMS) and must be reachable by thousands of distributed Grid worker nodes during reconstruction and analysis.
The authors first describe each experiment’s integration model. ATLAS couples the COOL (Conditions Database) framework with Oracle Real Application Clusters (RAC) and replicates the database to more than 150 sites worldwide. CMS adopts a hybrid HTTP‑based approach: the Frontier/Squid caching layer serves as a front‑end to MySQL/PostgreSQL back‑ends, delivering condition data via REST‑like queries. ALICE uses a local SQLite cache that synchronises with a central MySQL server, while LHCb runs a mixed Oracle/PostgreSQL environment accessed through a ROOT‑based DBI abstraction. The paper explains why these choices were made, citing factors such as licensing cost, scalability, operational expertise, and the need for high‑throughput read‑only access.
Next, concrete examples of database interfaces are presented. ATLAS provides a C++ COOL API with a Python wrapper that allows queries based on the Interval of Validity (IOV). CMS’s Frontier servers translate client requests into SQL, while Squid proxies cache the results, dramatically reducing latency for repeated queries. ALICE’s ROOT TSQLServer class offers a uniform query syntax for both SQLite and MySQL, simplifying user code. These abstractions decouple physics applications from the underlying DBMS, easing maintenance and future migrations.
The paper then analyses the characteristics of distributed database applications along four dimensions: data complexity, update frequency, data volume, and access patterns. Conditions data are highly structured, often requiring multi‑table joins and time‑versioning. Updates occur on a daily to weekly cadence (e.g., new calibration constants), whereas the total volume of conditions data is modest compared with event data (tens of terabytes per year). Nevertheless, the access frequency is enormous—millions of read operations per reconstruction campaign. Access patterns differ between reconstruction (massive, simultaneous reads of the same IOV) and analysis (heterogeneous reads spanning many IOVs).
Scalability tests are reported in detail. In ATLAS, an Oracle RAC cluster sustained an average query latency of 120 ms under a 10 k‑CPU reconstruction workload, but peak latency rose to >300 ms during contention spikes. CMS achieved a cache hit rate above 85 % with Frontier/Squid, which reduced network traffic and kept query latency under 100 ms; cache misses caused a two‑fold increase in latency as workers fell back to direct DB access. MySQL‑based deployments demonstrated lower licensing costs but exhibited connection‑pool bottlenecks when concurrent connections exceeded ~5 k, highlighting the need for more sophisticated pooling or sharding strategies.
Finally, the authors identify three open issues that remain critical for the upcoming High‑Luminosity LHC era. (1) Designing a hybrid architecture that can accommodate frequent real‑time updates while supporting the massive, read‑only workloads typical of reconstruction. (2) Establishing standardized protocols and policies for global cache consistency and improving cache hit ratios across heterogeneous sites. (3) Deploying AI‑driven monitoring and automated recovery tools to manage database health, predict failures, and orchestrate rapid fail‑over. The paper concludes that addressing these challenges will be essential to ensure that the next generation of LHC experiments can fully exploit the Grid’s computational power without being limited by database performance or reliability.
Comments & Academic Discussion
Loading comments...
Leave a Comment