Linguistic complexity: English vs. Polish, text vs. corpus
We analyze the rank-frequency distributions of words in selected English and Polish texts. We show that for the lemmatized (basic) word forms the scale-invariant regime breaks after about two decades, while it might be consistent for the whole range of ranks for the inflected word forms. We also find that for a corpus consisting of texts written by different authors the basic scale-invariant regime is broken more strongly than in the case of comparable corpus consisting of texts written by the same author. Similarly, for a corpus consisting of texts translated into Polish from other languages the scale-invariant regime is broken more strongly than for a comparable corpus of native Polish texts. Moreover, we find that if the words are tagged with their proper part of speech, only verbs show rank-frequency distribution that is almost scale-invariant.
💡 Research Summary
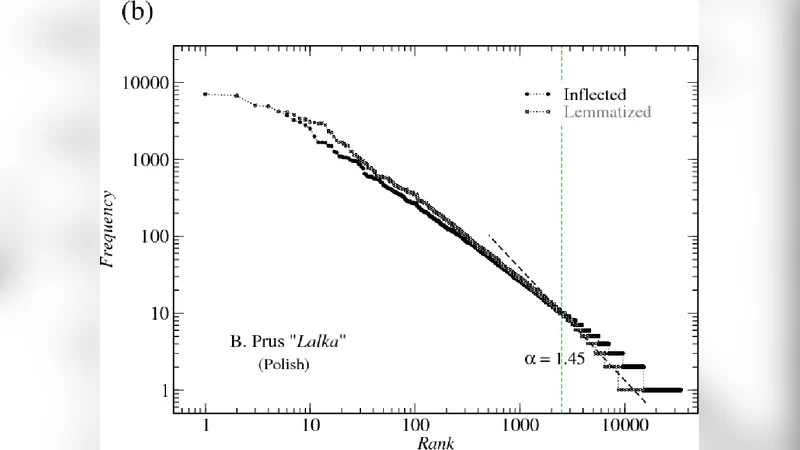
The paper investigates how well Zipf’s law – the empirical observation that word frequency is inversely proportional to its rank – holds for English and Polish under various linguistic processing conditions. The authors start by selecting a set of representative texts in both languages, then create two parallel representations for each text: (1) lemmatized forms, where inflectional morphology (plural, case, tense, gender, etc.) is stripped to yield a basic dictionary entry, and (2) fully inflected word forms as they appear in the original corpora. Using standard morphological analyzers and language‑specific dictionaries, they ensure a consistent mapping from surface tokens to lemmas.
Four corpora are then assembled: (a) a “single‑author” corpus consisting of several works by the same writer, (b) a “multi‑author” corpus that mixes texts from different writers, (c) a “native‑Polish” corpus of original Polish texts, and (d) a “translated‑Polish” corpus comprising works originally written in other languages and later translated into Polish. For each corpus and each representation (lemmas vs. inflected forms) the authors compute word frequencies, rank the words from most to least frequent, and plot the rank‑frequency relationship on log‑log axes.
The results reveal a systematic divergence between lemmas and inflected forms. Lemma‑based distributions display a clear break after roughly two orders of magnitude in rank (approximately ranks 10²–10³). Below this breakpoint the curve follows a straight line consistent with Zipf’s law, but above it the slope steepens, indicating a loss of scale‑invariance. In contrast, the distributions of inflected forms remain approximately linear over the entire observable range (up to rank 10⁵), suggesting that morphological variation smooths the frequency spectrum and preserves the power‑law behaviour.
When the authors compare corpora, they find that homogeneity matters. The single‑author lemma corpus retains a relatively long Zipf‑like regime, whereas the multi‑author corpus shows a much earlier breakdown, reflecting the diversity of vocabularies, styles, and topics across different writers. A similar pattern emerges for translation: the translated‑Polish lemma corpus deviates more strongly from a pure power law than the native‑Polish lemma corpus. The authors attribute this to the lexical and syntactic adjustments introduced during translation, which create a richer set of surface forms and disrupt the regularity of the underlying lemma frequencies.
A further layer of analysis tags each token with its part of speech (POS) and examines POS‑specific rank‑frequency curves. Nouns and adjectives exhibit pronounced curvature, especially at high ranks, while adverbs show intermediate behaviour. Strikingly, verbs alone maintain an almost perfect Zipfian scaling across the full rank spectrum, both for lemmas and inflected forms. This suggests that verbal elements, which carry core propositional content and are reused across contexts, obey a stronger scale‑invariant law than other lexical categories.
The authors conclude that (i) lemmatization, while useful for semantic analysis, reduces the range over which Zipf’s law holds; (ii) morphological richness in inflected languages like Polish can extend the power‑law regime; (iii) corpus composition—authorial homogeneity and translation status—significantly influences the degree of scale‑invariance; and (iv) among POS, verbs are the most robust carriers of Zipfian statistics. These findings have practical implications for statistical language modelling, corpus design, and the evaluation of machine translation systems, where preserving or deliberately altering Zipfian properties may affect downstream tasks such as language modelling, information retrieval, and lexical diversity measurement.
Comments & Academic Discussion
Loading comments...
Leave a Comment