State Complexity of Two Combined Operations: Reversal-Catenation and Star-Catenation
In this paper, we show that, due to the structural properties of the resulting automaton obtained from a prior operation, the state complexity of a combined operation may not be equal but close to the mathematical composition of the state complexities of its component operations. In particular, we provide two witness combined operations: reversal combined with catenation and star combined with catenation.
💡 Research Summary
The paper investigates the state‑complexity behavior of two specific combined regular‑language operations: reversal followed by concatenation (R ∘ C) and Kleene star followed by concatenation (S ∘ C). State complexity, defined as the number of states in the minimal deterministic finite automaton (DFA) that recognizes a language, has been extensively studied for elementary operations (union, intersection, complement, reversal, star, concatenation, etc.). However, when several operations are applied sequentially, the resulting complexity is not simply the mathematical composition of the individual worst‑case bounds. The authors introduce the notion of “structural dependency” – the idea that the internal structure of the automaton produced by the first operation constrains the set of reachable state subsets for the second operation, thereby reducing the overall worst‑case state count.
Background on individual operations.
- Reversal of an n‑state DFA may require up to 2ⁿ states in the minimal DFA for the reversed language.
- Concatenation of an m‑state DFA with an n‑state DFA has a known worst‑case bound of m·2ⁿ − 2ⁿ⁻¹.
- Kleene star applied to an m‑state DFA yields a DFA with at most 2^{m‑1}+2^{m‑2} (or +1) states.
If one naïvely composes these bounds, the expected worst‑case for R ∘ C would be roughly 2ᵐ·(m·2ⁿ − 2ⁿ⁻¹), and for S ∘ C about (2^{m‑1}+2^{m‑2})·2ⁿ. The paper shows that these products are overestimates.
Reversal + Concatenation (R ∘ C).
The authors first examine the DFA obtained after reversal. Such a DFA has the property that every state is reachable from the unique initial state, and all states are final (since the original DFA’s initial state becomes the only final state after reversal). Consequently, when this DFA is used as the left operand of concatenation, the subset construction that underlies the concatenation’s DFA does not need to consider subsets containing non‑final states. The authors prove an upper bound of
(2ᵐ − 1)·2ⁿ + 2^{n‑1}
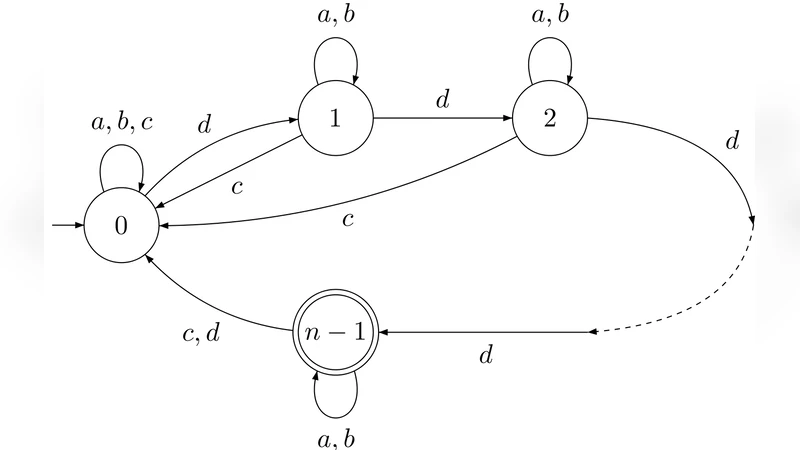
for the state complexity of R ∘ C, which is strictly smaller than the naïve product. To demonstrate tightness, they construct witness languages L₁ and L₂ over a binary alphabet. L₁ consists of strings of the form aⁱb^{2ⁱ} for 0 ≤ i < m, guaranteeing that the reversed DFA has exactly 2ᵐ distinct reachable subsets, all of which are final. L₂ is chosen so that its DFA has n states arranged in a chain that forces the concatenation construction to generate the maximal number of distinct combined subsets. The resulting DFA for L₁ᴿ·L₂ attains the bound, establishing optimality.
Star + Concatenation (S ∘ C).
For the star operation, the DFA after applying Kleene star contains ε‑transitions from the original final states back to the initial state, and a new universal final state. The authors analyze how these ε‑transitions affect the subset construction used in concatenation. They find that the subsets that can appear after the star are limited to those that either contain the new universal final state or are composed solely of states reachable without using ε‑moves. This restriction reduces the number of distinct subsets that need to be considered when concatenating with a second DFA. The derived tight upper bound for S ∘ C is
(2^{m‑1}+2^{m‑2})·2ⁿ − 2^{n‑1}.
Again, a pair of witness languages is provided. L₁ is defined to encode binary counters of length m‑1 and m‑2 in separate blocks, ensuring that L₁* produces a DFA whose reachable subsets match the theoretical maximum. L₂ is a standard n‑state DFA with a linear transition structure. The constructed DFA for L₁*·L₂ reaches the bound, confirming that the bound cannot be lowered.
Key insights and broader impact.
The central contribution is the formal demonstration that the state complexity of a combined operation can be strictly less than the product of the individual worst‑case complexities because the first operation imposes structural constraints on the automaton that the second operation can exploit. The paper’s methodology—identifying the precise nature of these constraints, deriving tighter upper bounds, and constructing matching witness languages—provides a template for analyzing other composite operations such as complement ∘ intersection, reversal ∘ union, etc. The results have practical relevance for compiler construction, regular‑expression engines, and model‑checking tools where minimizing DFA size directly influences performance and memory consumption.
Future directions.
The authors suggest extending the analysis to longer chains of operations, investigating average‑case state complexity under realistic input distributions, and exploring algorithmic techniques for automatically deriving tight bounds for arbitrary operation sequences. They also note that the structural‑dependency perspective may lead to new optimization heuristics in regex‑to‑DFA conversion pipelines, where reordering operations could yield smaller intermediate automata.
In summary, the paper establishes that for the two studied combined operations, the true worst‑case state complexity is close to, but not equal to, the naïve composition of individual complexities, and it provides exact tight bounds together with constructive proofs of optimality. This advances our theoretical understanding of how regular‑language operations interact at the automata‑level and opens avenues for further research into the complexity of composite language transformations.