Van Raan et al. (2010; arXiv:1003.2113) have proposed a new indicator (MNCS) for field normalization. Since field normalization is also used in the Leiden Rankings of universities, we elaborate our critique of journal normalization in Opthof & Leydesdorff (2010; arXiv:1002.2769) in this rejoinder concerning field normalization. Fractional citation counting thoroughly solves the issue of normalization for differences in citation behavior among fields. This indicator can also be used to obtain a normalized impact factor.
Deep Dive into Normalization at the field level: fractional counting of citations.
Van Raan et al. (2010; arXiv:1003.2113) have proposed a new indicator (MNCS) for field normalization. Since field normalization is also used in the Leiden Rankings of universities, we elaborate our critique of journal normalization in Opthof & Leydesdorff (2010; arXiv:1002.2769) in this rejoinder concerning field normalization. Fractional citation counting thoroughly solves the issue of normalization for differences in citation behavior among fields. This indicator can also be used to obtain a normalized impact factor.
We focused in Opthof & Leydesdorff (2010) on journal normalization because in the case of field normalization, one has two problems: the scientometric one of how to delineate fields and the statistical one of how to normalize. Journal normalization is the simpler case because journals are delineated units of analysis. Like CPP/FCSm, MNCS is based on the ISI Subject Categories for weighing citation scores at the field level. The ISI Subject Categories, however, were not designed for the scientometric evaluation, but for the purpose of information retrieval. Despite a strong denial by Van Raan et al. (2010) who formulate: "we are not aware of any convincing evidence of large-scale inaccuracies in the classification scheme of WoS," the subject categories lack an analytical base (Pudovkin & Garfield, 2002, at p. 1113n.;Rafols & Leydesdorff, 2009) and are not literary-warranted (Bensman & Leydesdorff, 2009). Several alternatives for the classification have been proposed (Bornmann, 2010;Glänzel & Schubert, 2003).
In our opinion, the purpose of normalization at the field level is to control for differences in expected citation frequencies among fields (Garfield, 1979, at p. 366;McAllister et al., 1983;Moed, 2010b). These differences are caused by differences in citation behavior among scholars in various fields of science. Mathematics, for example, is known to have a much lower citation density than the biomedical sciences. In our opinion, the easiest way to capture the differences in citation behavior among fields is by fractional counting in the citing articles at the article level (Small & Sweeney, 1985). For example, if an author in mathematics cites six references, each reference can be counted as 1/6 of overall citation, whereas a citation in a paper in biomedicine with 40 cited references can be counted as 1/40. This normalization thoroughly takes field differences into account and the results allow for statistical testing. Most importantly, the normalization is independent from a classification system and thus there is no indexer effect.
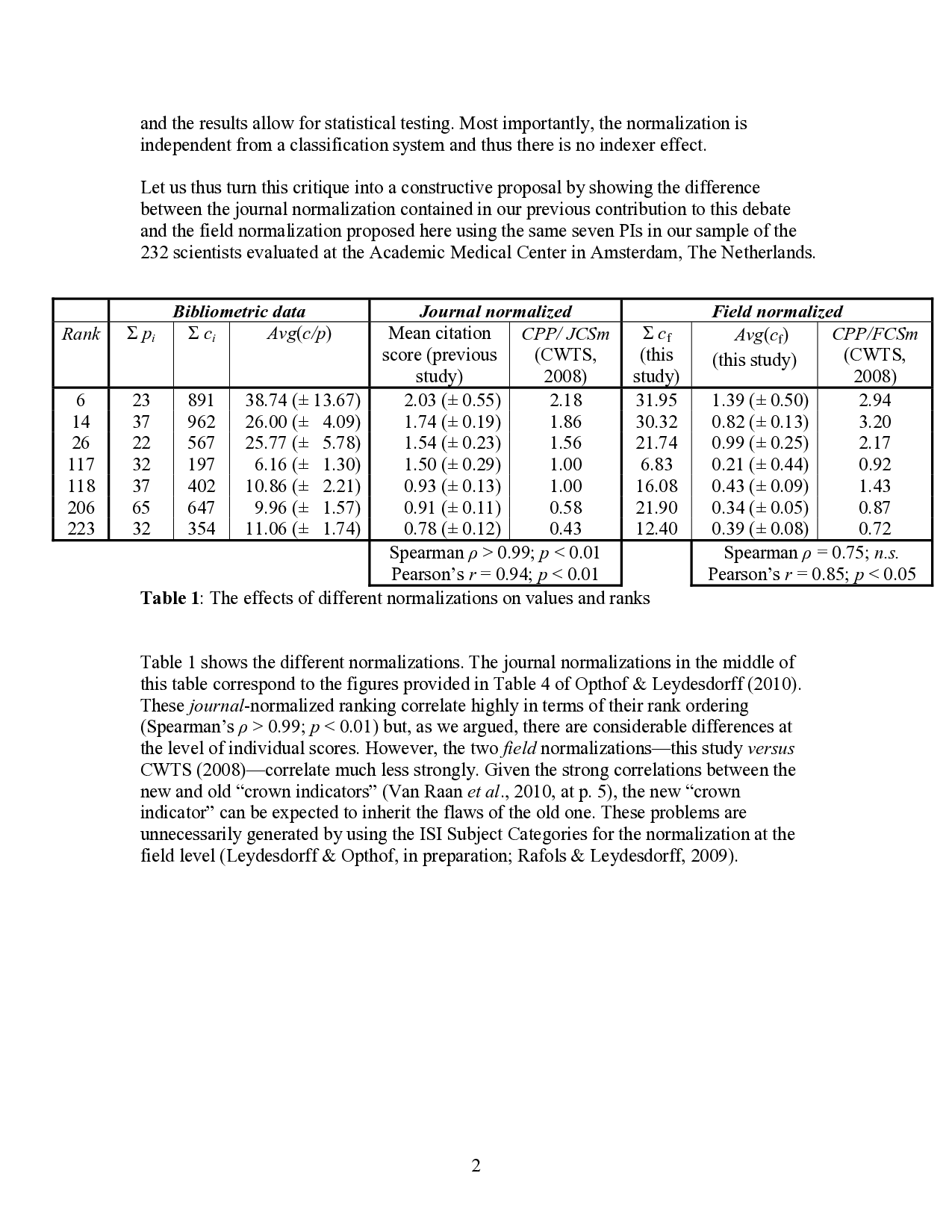
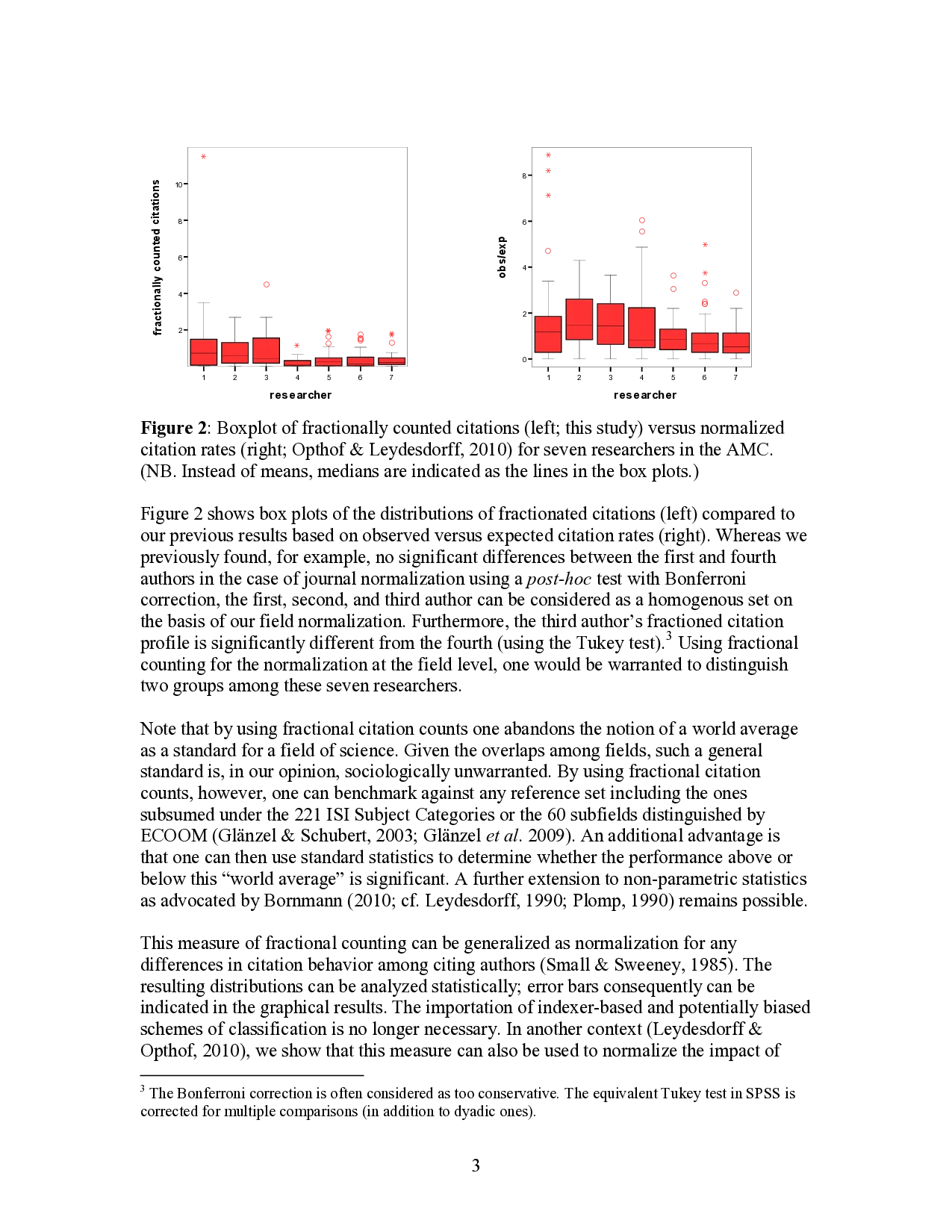
Let us thus turn this critique into a constructive proposal by showing the difference between the journal normalization contained in our previous contribution to this debate and the field normalization proposed here using the same seven PIs in our sample of the 232 scientists evaluated at the Academic Medical Center in Amsterdam, The Netherlands. 4 of Opthof & Leydesdorff (2010). These journal-normalized ranking correlate highly in terms of their rank ordering (Spearman’s ρ > 0.99; p < 0.01) but, as we argued, there are considerable differences at the level of individual scores. However, the two field normalizations-this study versus CWTS (2008)-correlate much less strongly. Given the strong correlations between the new and old “crown indicators” (Van Raan et al., 2010, at p. 5), the new “crown indicator” can be expected to inherit the flaws of the old one. These problems are unnecessarily generated by using the ISI Subject Categories for the normalization at the field level (Leydesdorff & Opthof, in preparation;Rafols & Leydesdorff, 2009). Figure 2 shows box plots of the distributions of fractionated citations (left) compared to our previous results based on observed versus expected citation rates (right). Whereas we previously found, for example, no significant differences between the first and fourth authors in the case of journal normalization using a post-hoc test with Bonferroni correction, the first, second, and third author can be considered as a homogenous set on the basis of our field normalization. Furthermore, the third author’s fractioned citation profile is significantly different from the fourth (using the Tukey test). 3 Using fractional counting for the normalization at the field level, one would be warranted to distinguish two groups among these seven researchers.
Note that by using fractional citation counts one abandons the notion of a world average as a standard for a field of science. Given the overlaps among fields, such a general standard is, in our opinion, sociologically unwarranted. By using fractional citation counts, however, one can benchmark against any reference set including the ones subsumed under the 221 ISI Subject Categories or the 60 subfields distinguished by ECOOM (Glänzel & Schubert, 2003;Glänzel et al. 2009). An additional advantage is that one can then use standard statistics to determine whether the performance above or below this “world average” is significant. A further extension to non-parametric statistics as advocated by Bornmann (2010;cf. Leydesdorff, 1990;Plomp, 1990) remains possible.
This measure of fractional counting can be generalized as normalization for any differences in citation behavior among citing authors (Small & Sweeney, 1985). The resulting distributions can be analyzed statistically; error bars consequently can be indicated in the graphical results. The importation of indexer-based and potentially biase
…(Full text truncated)…
This content is AI-processed based on ArXiv data.