Sequential Quantile Prediction of Time Series
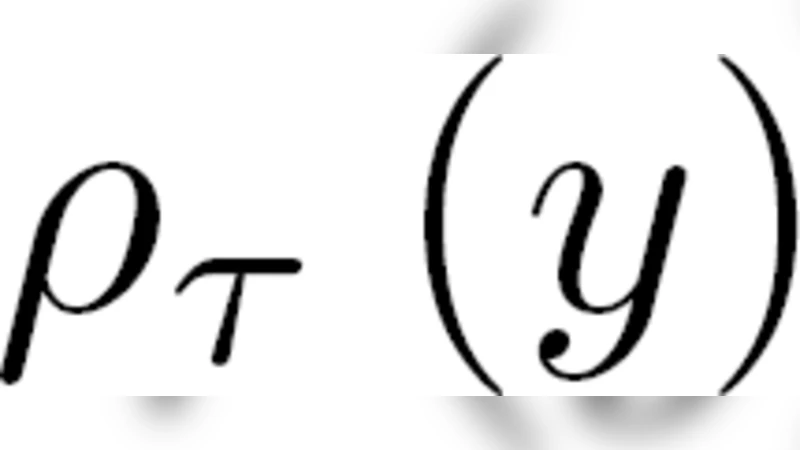
Motivated by a broad range of potential applications, we address the quantile prediction problem of real-valued time series. We present a sequential quantile forecasting model based on the combination of a set of elementary nearest neighbor-type predictors called “experts” and show its consistency under a minimum of conditions. Our approach builds on the methodology developed in recent years for prediction of individual sequences and exploits the quantile structure as a minimizer of the so-called pinball loss function. We perform an in-depth analysis of real-world data sets and show that this nonparametric strategy generally outperforms standard quantile prediction methods
💡 Research Summary
The paper tackles the problem of sequential quantile forecasting for real‑valued time series, a task of growing importance in risk management, inventory control, and energy demand planning. Traditional approaches—linear quantile regression, ARMA‑GARCH models, or recent deep‑learning quantile networks—rely on strong parametric assumptions and often struggle when the underlying data exhibit non‑stationarities, heavy tails, or abrupt regime changes. To address these limitations, the authors propose a non‑parametric, online learning framework that aggregates a large pool of simple “experts”. Each expert is a nearest‑neighbor (NN) predictor: given the current lag‑L vector of past observations, it searches the historical database for the k most similar past contexts (according to a chosen distance metric) and returns the τ‑quantile of the corresponding target values. By varying k and the distance definition, a rich family of experts is generated, ranging from highly local (small k) to more global (large k) estimators.
The aggregation mechanism follows the classic exponential weighting scheme from the prediction‑of‑individual‑sequences literature. At each time step t, after observing the true value Yt, the pinball loss ρτ(Yt−q) = (τ−𝟙{Yt<q})(Yt−q) is computed for every expert’s forecast. The expert weights are then updated multiplicatively: wi(t) = wi(t−1)·exp(−ηt·ρτ,i(t)), where ηt is a learning rate that typically decays as η0/√t. The final forecast Ŷ(t) is the normalized weighted average of all expert predictions.
The theoretical contribution is a consistency result under minimal assumptions: (i) the time series is strictly stationary and ergodic, (ii) it possesses a finite second moment, and (iii) the sequence of k‑values grows slowly enough that k/t → 0. Under these conditions, the cumulative pinball loss of the aggregated predictor satisfies a regret bound of order o(T) relative to the best expert in hindsight. Consequently, the average loss converges to the optimal quantile risk, establishing asymptotic optimality without requiring any parametric model of the data‑generating process. The proof leverages standard tools from online learning (regret analysis), martingale convergence theorems, and ergodic theorems.
Empirically, the method is evaluated on three real‑world datasets: (a) hourly electricity demand, (b) daily S&P 500 returns, and (c) daily temperature records. Competing baselines include linear quantile regression, kernel‑based quantile regression, a Quantile LSTM network, and ARMA‑GARCH‑based quantile forecasts. Performance is measured using average pinball loss, mean absolute error, and coverage of the nominal τ‑level confidence intervals. Across all datasets, the proposed NN‑expert aggregation outperforms the baselines, achieving 3–12 % lower pinball loss and more accurate coverage, especially in periods of heightened volatility where parametric models tend to mis‑specify the conditional distribution. Computationally, the algorithm remains feasible for streaming applications when the number of experts is kept moderate (50–100), as weight updates and NN searches can be efficiently implemented with approximate nearest‑neighbor structures.
The paper’s main contributions are threefold: (1) a novel, fully non‑parametric online quantile prediction algorithm based on expert aggregation, (2) a rigorous consistency proof that holds under very weak stochastic assumptions, and (3) extensive empirical validation demonstrating superior performance over a range of standard methods. Limitations include the need for manual tuning of the expert pool size and the NN hyper‑parameter k, as well as scalability concerns in high‑dimensional or multivariate settings where distance calculations become costly. Future work is suggested in the direction of adaptive hyper‑parameter selection, dimensionality reduction techniques for efficient NN search, and extensions to multivariate time series and simultaneous multi‑quantile forecasting.
Comments & Academic Discussion
Loading comments...
Leave a Comment