Towards a stable definition of Kolmogorov-Chaitin complexity
Although information content is invariant up to an additive constant, the range of possible additive constants applicable to programming languages is so large that in practice it plays a major role in the actual evaluation of K(s), the Kolmogorov-Chaitin complexity of a string s. Some attempts have been made to arrive at a framework stable enough for a concrete definition of K, independent of any constant under a programming language, by appealing to the “naturalness” of the language in question. The aim of this paper is to present an approach to overcome the problem by looking at a set of models of computation converging in output probability distribution such that that “naturalness” can be inferred, thereby providing a framework for a stable definition of K under the set of convergent models of computation.
💡 Research Summary
The paper addresses a fundamental practical problem in algorithmic information theory: the Kolmogorov‑Chaitin complexity K(s) of a binary string s depends on the choice of universal Turing machine (or programming language) through an additive constant. While the Invariance Theorem guarantees the existence of a constant C such that |K₁(s) – K₂(s)| ≤ C for any two universal machines, the magnitude of C can be arbitrarily large, especially for short strings, rendering the theoretical definition of K of limited use in empirical work.
To mitigate this issue, the authors propose a novel “naturalness” criterion based on the convergence of output probability distributions across different models of computation. The central hypothesis is that if several computational models produce similar distributions of strings after running for a comparable amount of time, then the additive constants between them must be small, and the relative ordering of K-values will be preserved.
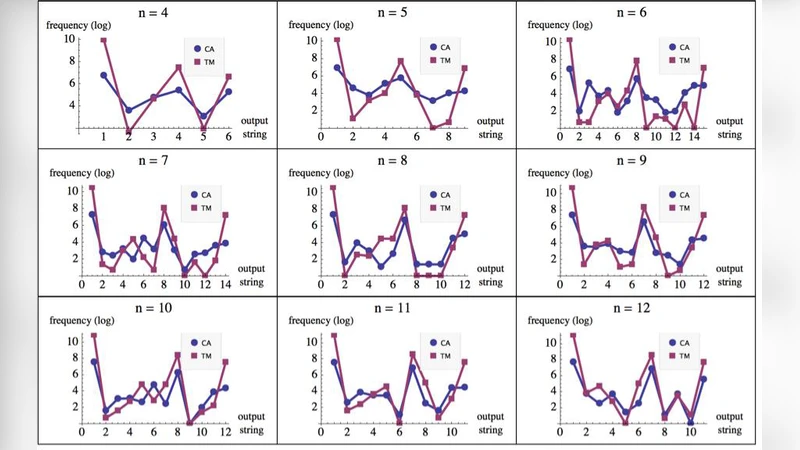
The experimental framework focuses on two well‑studied families of universal computers: (i) the set TM(2,2) of all 2‑state, 2‑symbol deterministic Turing machines (4096 machines) and (ii) the set CA(1) of elementary one‑dimensional cellular automata (256 rules). Each machine is run for t = n·10 steps (e.g., 30 steps for strings of length n = 3) on two complementary initial tapes (all‑0 and all‑1). After execution, the binary strings of length n that appear on the visited cells are recorded, and the empirical frequency of each string is used to build a discrete probability distribution D.
The authors find a striking correlation between the two distributions. For n = 3, the strings are grouped into six symmetry classes (identity, reversal, complementation, and their compositions). Within each class, the frequencies from TM(2,2) and CA(1) match almost perfectly, despite occasional crossings of individual strings. Similar results are reported for n = 4. This suggests that the two computational families share a common “natural” bias toward certain strings, and that the bias is invariant under the simple symmetries of reversal and bit‑wise complement.
To formalize the notion of symmetry, the paper invokes the Pólya‑Burnside enumeration theorem. The transformation group T consists of four operations: the identity, reversal (sy), complementation (co), and their composition (sy∘co). Applying Burnside’s lemma yields the number of distinct complexity classes (sets of strings with equal K) as (2ⁿ + 2·2ⁿ⁄²)/4 for odd n and (2ⁿ + 2·(n+1)/2)/4 for even n. By collapsing each symmetry class into a single representative, the authors obtain a reduced distribution Dʳ that eliminates rank‑ordering artifacts caused by swapping symmetric strings (e.g., (0)ⁿ versus (1)ⁿ).
The key insight is that when two models produce the same reduced distribution Dʳ, the additive constant between their respective universal machines must be bounded by a small value, because the probability of each string is directly related to its algorithmic probability m(s) = 2^{-K(s)+O(1)}. Consequently, the relative ordering of K(s) across strings is stable across the models. This stability holds even for short strings, where traditional compression‑based estimates of K are heavily distorted by large constants.
The authors argue that the convergence observed between TM(2,2) and CA(1) provides an empirical foundation for a “natural” class of computational models. Within this class, K(s) can be estimated in a way that is largely independent of the underlying programming language, thereby offering a more objective and reproducible measure of algorithmic information. They suggest that extending the analysis to other families (e.g., larger state‑symbol Turing machines, higher‑dimensional cellular automata, or other universal formalisms) could further validate the approach and possibly define a broader notion of naturalness.
In summary, the paper contributes a concrete experimental methodology for reducing the language‑dependence of Kolmogorov‑Chaitin complexity. By demonstrating that distinct universal models can share a convergent output distribution and by using group‑theoretic symmetry reduction to define complexity classes, the authors provide a pathway toward a stable, practically usable definition of K that respects the theoretical invariance while mitigating the impact of large additive constants. This work bridges the gap between the abstract, uncomputable definition of algorithmic complexity and its empirical estimation, opening avenues for more reliable applications in data compression, randomness testing, and the quantitative study of complex systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment