Using Soft Constraints To Learn Semantic Models Of Descriptions Of Shapes
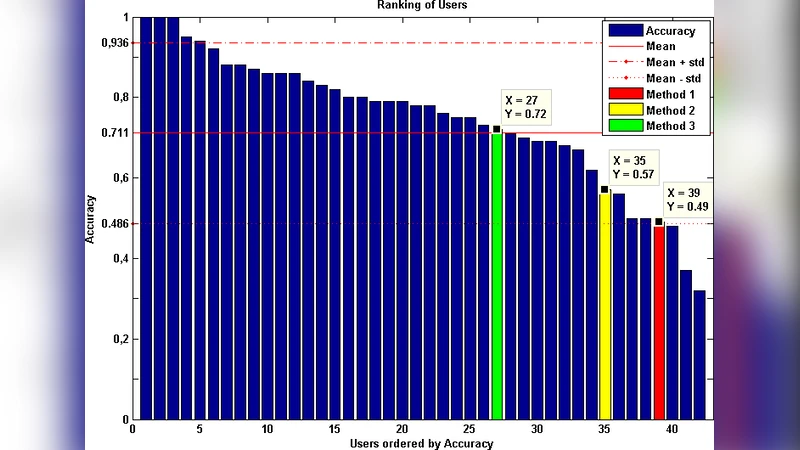
The contribution of this paper is to provide a semantic model (using soft constraints) of the words used by web-users to describe objects in a language game; a game in which one user describes a selected object of those composing the scene, and another user has to guess which object has been described. The given description needs to be non ambiguous and accurate enough to allow other users to guess the described shape correctly. To build these semantic models the descriptions need to be analyzed to extract the syntax and words’ classes used. We have modeled the meaning of these descriptions using soft constraints as a way for grounding the meaning. The descriptions generated by the system took into account the context of the object to avoid ambiguous descriptions, and allowed users to guess the described object correctly 72% of the times.
💡 Research Summary
The paper presents a novel approach for grounding natural‑language descriptions of visual objects by learning semantic models with soft constraints. The authors built a web‑based “language game” in which two participants interact with a shared scene containing several geometric shapes that differ in color, size, form, and spatial location. One player selects a target shape and provides a short textual description (typically three to five words). The second player must identify the target based solely on that description. Over 500 game rounds were recorded, yielding more than 2,000 description‑target pairs.
The first analytical step involved linguistic processing: each description was tokenized, part‑of‑speech tagged, and parsed to extract noun phrases, adjectives, and prepositional phrases. The extracted lexical items were then mapped to five pre‑defined semantic classes—color, size, shape, position, and relational context. Ambiguous words (e.g., “small”) were disambiguated using contextual cues, and multi‑sense words were assigned to the class with the highest posterior probability.
To capture the inherent fuzziness of everyday language, the authors employed soft constraints, i.e., fuzzy logic, rather than binary hard constraints. For each semantic class a membership function was defined: color membership was derived from distances in the CIELAB space, size from normalized area, and position from Euclidean distances relative to scene landmarks. A description’s compatibility with a particular shape was computed by aggregating the fuzzy values of all its constituent words, typically using a product (or minimum) operator, yielding a “fit score.”
Because a description may be ambiguous when multiple shapes share the same attributes, the system automatically augments the description with additional discriminative properties. This context‑aware expansion is driven by an information‑gain criterion: the attribute that most reduces the candidate set is appended (e.g., “the blue circle” becomes “the blue circle in the upper‑left corner”). The resulting description is thus both concise and unambiguous with respect to the current scene.
The generated descriptions were then presented to human participants, who attempted to locate the target shape. The experimental outcome showed a 72 % success rate, a substantial improvement over random guessing (≈20 %). Error analysis revealed that most failures stemmed from color confusion (e.g., distinguishing “light blue” from “cyan”) and vague positional language (“near the left”).
The authors acknowledge several limitations: the current framework handles only two‑dimensional primitive shapes, lacks support for complex relational expressions (e.g., “between A and B”), and relies on manually crafted membership functions. They propose future work that integrates graph‑based scene representations, learns fuzzy membership functions via deep neural networks, and incorporates online user feedback to adapt descriptions in real time.
In summary, this study demonstrates that soft‑constraint modeling can effectively bridge natural language and visual perception, providing a mathematically grounded method for handling linguistic uncertainty. The language‑game methodology supplies authentic user data for training and evaluation, and the reported 72 % identification accuracy validates the practical viability of the approach. The work lays a solid foundation for more sophisticated multimodal systems that require robust grounding of ambiguous human descriptions.
Comments & Academic Discussion
Loading comments...
Leave a Comment