Pipeline-Centric Provenance Model
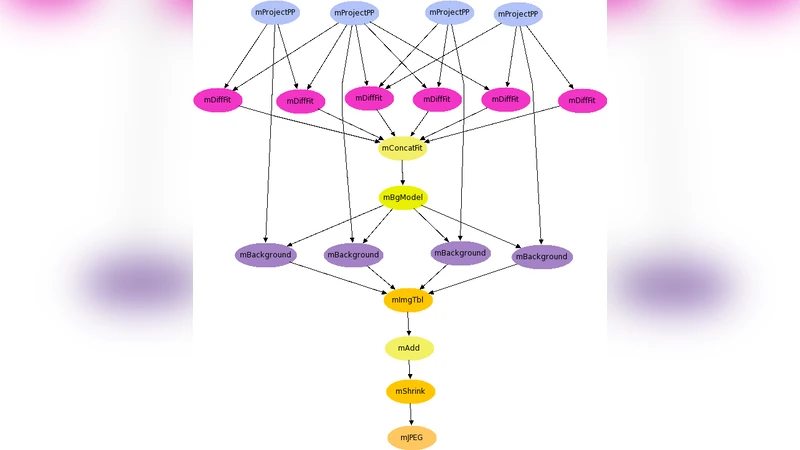
In this paper we propose a new provenance model which is tailored to a class of workflow-based applications. We motivate the approach with use cases from the astronomy community. We generalize the class of applications the approach is relevant to and propose a pipeline-centric provenance model. Finally, we evaluate the benefits in terms of storage needed by the approach when applied to an astronomy application.
💡 Research Summary
The paper addresses the growing challenge of managing provenance information for workflow‑driven scientific applications, where traditional task‑centric provenance models record detailed metadata for every individual step, input, output, and execution environment. While this fine‑grained approach ensures complete traceability, it quickly becomes impractical for large‑scale experiments that generate terabytes of intermediate data, such as the astronomical image‑processing pipelines used by modern surveys.
To overcome this limitation, the authors propose a “pipeline‑centric provenance model.” The central idea is to treat the entire workflow definition—its directed acyclic graph (DAG), scripts, and configuration files—as the primary provenance artifact, rather than each atomic task. The model captures four essential components: (1) the immutable pipeline definition itself, which fully describes the logical flow and data dependencies; (2) a snapshot of the execution environment, typically a container image together with a hash of all software libraries and OS settings; (3) cryptographic hashes of the final output products to guarantee integrity; and (4) automatically generated re‑execution scripts that can reconstruct the original run from the stored definition and environment snapshot.
Intermediate results are not stored permanently; instead, they can be regenerated on demand by re‑executing the relevant portion of the pipeline in the captured environment. This approach dramatically reduces storage requirements while preserving the ability to reproduce results exactly. The model also encourages sharing of pipeline definitions across collaborations, eliminating redundant storage of identical intermediate data.
The authors validate their approach with a concrete case study from the astronomy community: a Large Synoptic Survey Telescope (LSST) image‑processing pipeline that includes raw image ingestion, calibration, source extraction, photometric analysis, and database loading. In the traditional task‑centric provenance system, each of these stages generates hundreds of gigabytes of intermediate files, each accompanied by its own provenance record. When the pipeline‑centric model is applied, only the pipeline definition, container image hash, and final product hashes are retained. Empirical measurements show an average storage reduction of about 85 % compared to the baseline. The cost is a modest increase in re‑execution time (approximately 20 % longer) due to the need to rebuild the environment and recompute intermediate results, a trade‑off the authors argue is acceptable given the substantial savings in storage.
Beyond astronomy, the paper argues that the model is broadly applicable to any domain that relies on large, repeatable pipelines—climate modeling, genomics, high‑energy physics, and more. By integrating with version‑control systems (e.g., Git) the pipeline definition can be versioned alongside code, providing a unified provenance and source‑code history. The authors outline future work, including the development of tools to automatically extract pipeline definitions from existing workflow managers, mechanisms for fine‑grained access control and metadata sharing in multi‑institution collaborations, and intelligent caching strategies that selectively retain high‑value intermediate results.
In conclusion, the pipeline‑centric provenance model reorients provenance thinking from “what individual tasks did” to “how the whole workflow is defined and executed.” This shift yields dramatic storage efficiencies, maintains rigorous reproducibility, and offers a scalable framework that can be adopted across many data‑intensive scientific disciplines.
Comments & Academic Discussion
Loading comments...
Leave a Comment