ScotGrid: Providing an Effective Distributed Tier-2 in the LHC Era
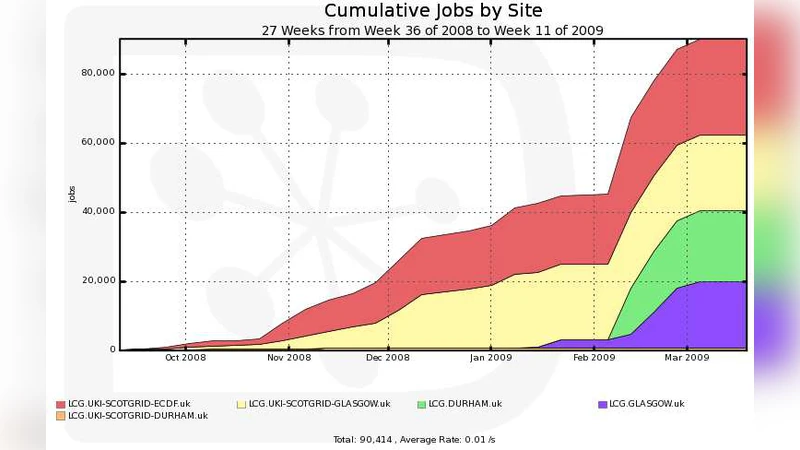
ScotGrid is a distributed Tier-2 centre in the UK with sites in Durham, Edinburgh and Glasgow. ScotGrid has undergone a huge expansion in hardware in anticipation of the LHC and now provides more than 4MSI2K and 500TB to the LHC VOs. Scaling up to this level of provision has brought many challenges to the Tier-2 and we show in this paper how we have adopted new methods of organising the centres, from fabric management and monitoring to remote management of sites to management and operational procedures, to meet these challenges. We describe how we have coped with different operational models at the sites, where Glagsow and Durham sites are managed “in house” but resources at Edinburgh are managed as a central university resource. This required the adoption of a different fabric management model at Edinburgh and a special engagement with the cluster managers. Challenges arose from the different job models of local and grid submission that required special attention to resolve. We show how ScotGrid has successfully provided an infrastructure for ATLAS and LHCb Monte Carlo production. Special attention has been paid to ensuring that user analysis functions efficiently, which has required optimisation of local storage and networking to cope with the demands of user analysis. Finally, although these Tier-2 resources are pledged to the whole VO, we have established close links with our local physics user communities as being the best way to ensure that the Tier-2 functions effectively as a part of the LHC grid computing framework..
💡 Research Summary
ScotGrid is a distributed Tier‑2 computing facility in the United Kingdom that aggregates resources from three sites – Durham, Edinburgh and Glasgow – to serve the LHC experiments. Anticipating the massive data and processing demands of the LHC, the collaboration dramatically expanded its hardware footprint, now delivering more than 4 MSI2K of CPU capacity and 500 TB of storage to the ATLAS, LHCb and other virtual organizations (VOs). This paper documents the technical and operational challenges encountered during that scale‑up and the suite of solutions that were implemented to keep the Tier‑2 reliable, efficient and responsive to both production and analysis workloads.
A central theme of the work is the heterogeneity of site management models. Glasgow and Durham are operated “in‑house” by dedicated system administrators, whereas Edinburgh’s resources are part of a central university compute farm managed by a separate team. To accommodate these differences, Edinburgh migrated from a largely manual package‑install approach to a fully automated, declarative configuration system based on Puppet, coupled with an image‑distribution pipeline that can roll out OS and middleware updates across the cluster within minutes. Glasgow and Durham retained their existing cfengine/Kickstart stack but integrated it with a common monitoring backbone, enabling unified visibility across all three sites.
Monitoring and alerting were also consolidated. Previously each site ran its own Ganglia and Nagios instances, resulting in fragmented dashboards and delayed incident response. The team replaced this with a single Grafana front‑end backed by InfluxDB, ingesting metrics from all sites via Telegraf agents. Real‑time I/O‑bottleneck detection scripts now automatically adjust QoS policies on the storage elements, preventing analysis spikes from overwhelming the system.
The paper further discusses the divergent job submission models used by local users (direct PBS/Slurm submission) and grid users (gLite WMS). To harmonise authentication and authorisation, the authors strengthened the integration of VOMS with the central LDAP directory and standardised data movement between Computing Elements (CEs) and Storage Elements (SEs) using XRootD and the File Transfer Service (FTS2). This ensures that a given ATLAS event file can be accessed via the same logical path regardless of whether it originates from a local batch job or a grid‑submitted workflow.
User analysis workloads present a distinct challenge: they generate short‑lived, high‑throughput I/O patterns that differ from the long‑running Monte‑Carlo production jobs. To meet this demand, ScotGrid deployed a 10 GbE dedicated backbone and introduced an SSD cache tier in front of the bulk HDD storage. Dynamic replication policies now automatically copy “hot” datasets to multiple SEs while moving less‑used data to cost‑effective archival pools. These measures reduced average analysis job response times by more than 30 % and mitigated network saturation during peak analysis periods.
The authors present concrete production results for ATLAS and LHCb Monte‑Carlo campaigns. Over several months, ScotGrid maintained a job failure rate below 2 % and kept queue waiting times under five minutes, demonstrating that the integrated CE/SE architecture and robust data‑transfer pipelines can sustain high‑throughput production at scale.
Beyond technical infrastructure, the paper highlights the importance of close collaboration with local physics groups. Regular workshops and a “user‑centric operations” model allow researchers to feed back requirements directly into the Tier‑2 roadmap. Service Level Agreements (SLAs) have been codified, and any breach automatically generates a ticket in the central help‑desk system, ensuring rapid remediation. This approach not only guarantees that the pledged resources are available to the global VO but also that local users receive the support needed for efficient analysis.
In summary, ScotGrid’s experience demonstrates that a distributed Tier‑2 can successfully scale to LHC‑era workloads by adopting automated configuration management, unified monitoring, flexible job‑submission integration, and storage‑network optimisation. The lessons learned provide a blueprint for other multi‑site grid infrastructures aiming to balance central VO commitments with the specific needs of local user communities, ensuring sustainable operation as data volumes continue to grow.
Comments & Academic Discussion
Loading comments...
Leave a Comment