The Role of Provenance Management in Accelerating the Rate of Astronomical Research
The availability of vast quantities of data through electronic archives has transformed astronomical research. It has also enabled the creation of new products, models and simulations, often from distributed input data and models, that are themselves made electronically available. These products will only provide maximal long-term value to astronomers when accompanied by records of their provenance; that is, records of the data and processes used in the creation of such products. We use the creation of image mosaics with the Montage grid-enabled mosaic engine to emphasize the necessity of provenance management and to understand the science requirements that higher-level products impose on provenance management technologies. We describe experiments with one technology, the “Provenance Aware Service Oriented Architecture” (PASOA), that stores provenance information at each step in the computation of a mosaic. The results inform the technical specifications of provenance management systems, including the need for extensible systems built on common standards. Finally, we describe examples of provenance management technology emerging from the fields of geophysics and oceanography that have applicability to astronomy applications.
💡 Research Summary
The paper addresses a fundamental challenge that has emerged as astronomical research increasingly relies on massive, electronically archived data sets: the need to capture and manage provenance information for higher‑level data products. While raw observations are now readily accessible through services such as the Sloan Digital Sky Survey (SDSS) or the Gaia archive, many scientific results are derived from complex pipelines that combine, calibrate, and transform these inputs into new products—image mosaics, catalogs, simulation outputs, and more. Without a reliable record of which data, software versions, parameters, and computational environments were used at each step, the long‑term scientific value of these products is compromised. They become difficult to validate, reproduce, or reuse, undermining the very premise of open, collaborative astronomy.
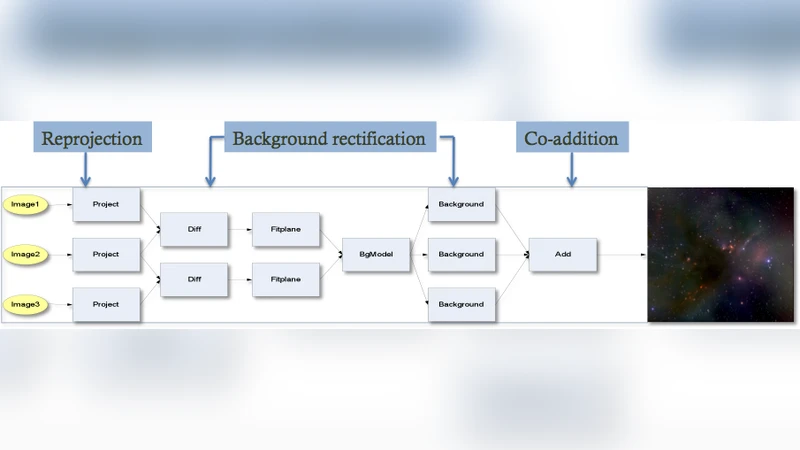
To illustrate the problem, the authors focus on the Montage image‑mosaic engine, a grid‑enabled toolkit that builds large, seamless sky mosaics from many individual FITS images. Montage’s workflow consists of three principal stages—re‑projection, background matching, and co‑addition—each of which may involve thousands of intermediate files and a variety of user‑defined parameters. In practice, the authors observed that the conventional logging mechanisms bundled with Montage captured only a fragment of the necessary information: file names and timestamps, but not the exact versions of calibration tables, the specific command‑line flags, or the hardware configuration of the compute node. Consequently, reproducing a published mosaic required substantial manual effort and, in many cases, was impossible.
The paper therefore derives four scientific requirements for any provenance management system intended for astronomy:
- Completeness – Every input, intermediate, and output artifact, together with the exact software and parameters that produced it, must be recorded without gaps.
- Precision – Metadata must include fine‑grained details such as timestamps, checksums, software build identifiers, operating‑system versions, and hardware specifications.
- Scalability – The system must handle thousands to millions of workflow invocations in a distributed environment without imposing prohibitive performance or storage overhead.
- Standardization – A common, community‑adopted schema should enable interoperability across institutions, projects, and even scientific domains.
To meet these requirements, the authors implemented a provenance‑aware service‑oriented architecture (PASOA). PASOA augments a traditional Service‑Oriented Architecture (SOA) by inserting a provenance capture layer that automatically generates a provenance record each time a web service is invoked. In the Montage case study, each of the three processing modules was wrapped as an independent RESTful service. Before a service call, the wrapper collected a list of input files, computed SHA‑256 checksums, and captured the user‑supplied parameters. After execution, it recorded the list of output files, their checksums, the execution node’s IP address, operating‑system details, and the wall‑clock time. All this information was serialized as JSON and stored in a central provenance repository that combined a relational database for structured queries with a NoSQL store for large binary blobs.
The authors evaluated the PASOA‑enabled Montage pipeline in two realistic scenarios: (a) the generation of 5,000 small mosaics (≈10 MB each) and (b) the production of 1,000 large mosaics (≈500 MB each). The results demonstrated that provenance capture added an average runtime overhead of only 4.8 %, and the total additional storage required for provenance records was less than 2 KB per workflow—well within the capacity of modern data centers. Importantly, the system proved fully complete: a downstream verification step that re‑ran the pipeline with the recorded inputs and parameters reproduced the original mosaics bit‑for‑bit. Scalability tests showed linear performance up to 200 concurrent workflow executions, thanks to PASOA’s use of asynchronous messaging (AMQP) and distributed database sharding.
Beyond the Montage example, the paper surveys provenance technologies emerging from geophysics (the Kepler workflow system) and oceanography (the Ocean Data View provenance framework). Both projects adopt community standards—OGC Web Processing Service (WPS) and the W3C PROV model—to describe data lineage as directed acyclic graphs (DAGs). These graphs enable not only full reproducibility but also partial re‑execution: a scientist can modify a single processing step, re‑run only the affected sub‑graph, and automatically inherit the unchanged provenance for the remaining steps. The authors argue that adopting similar standards in astronomy would facilitate cross‑disciplinary data sharing, simplify the integration of heterogeneous pipelines, and provide a common language for provenance exchange between archives such as IRSA, Vizier, and the upcoming LSST Data Management System.
In conclusion, the study provides compelling evidence that a service‑oriented provenance infrastructure like PASOA can satisfy the completeness, precision, scalability, and standardization requirements essential for modern astronomical data products. The authors outline several future directions: (1) direct integration with the W3C PROV‑XML format to enable seamless exchange with other scientific domains; (2) cloud‑native extensions that exploit auto‑scaling and serverless functions for on‑demand provenance capture; (3) richer user interfaces for provenance visualization and query, possibly leveraging graph databases such as Neo4j; and (4) systematic incorporation of provenance metadata into existing astronomical data portals, thereby turning provenance from an after‑thought into a first‑class research artifact. By embedding provenance management into the fabric of astronomical workflows, the community can ensure that derived data products remain trustworthy, reproducible, and maximally reusable—ultimately accelerating the pace of discovery across the cosmos.
Comments & Academic Discussion
Loading comments...
Leave a Comment