An Integrated Framework for Performance Analysis and Tuning in Grid Environment
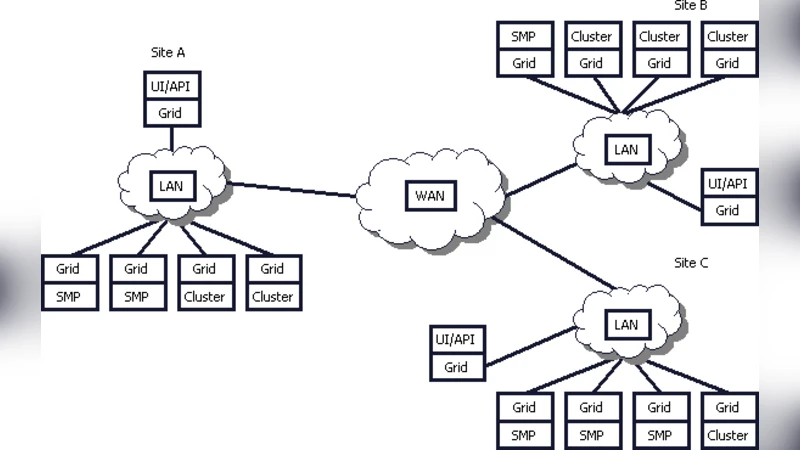
In a heterogeneous, dynamic environment, like Grid, post-mortem analysis is of no use and data needs to be collected and analysed in real time. Novel techniques are also required for dynamically tuning the application’s performance and resource brokering in order to maintain the desired QoS. The objective of this paper is to propose an integrated framework for performance analysis and tuning of the application, and rescheduling the application, if necessary, to some other resources in order to adapt to the changing resource usage scenario in a dynamic environment.
💡 Research Summary
The paper presents an integrated framework designed to continuously monitor, analyze, and improve the performance of applications running in heterogeneous, dynamic Grid environments. Recognizing that traditional post‑mortem analysis is ineffective when resources and workloads fluctuate rapidly, the authors propose a real‑time, multi‑layered architecture that couples performance data collection with automatic tuning and resource brokering. At the lowest level, lightweight sensors and agents are deployed on each node to gather fine‑grained metrics such as CPU utilization, memory pressure, I/O latency, network bandwidth, and power consumption. These metrics are streamed asynchronously to a local performance manager that normalizes the data, detects anomalies, and runs short‑term predictive models (e.g., ARIMA, LSTM) to anticipate upcoming load spikes.
A global tuning manager sits above the local managers and contains a policy engine that dynamically adjusts application‑level parameters (thread pool size, data chunk size, cache policies, etc.) based on current QoS targets (response time, throughput) and the observed resource state. The policy engine employs multi‑objective optimization techniques, including genetic algorithms and Pareto‑front analysis, to select the most beneficial configuration. Parallel to tuning, a resource broker evaluates the load, network latency, and data locality of all candidate nodes. When a node becomes overloaded or a QoS violation is imminent, the broker computes a cost‑benefit model that accounts for checkpoint overhead, data transfer volume, and expected performance gain, then decides whether to migrate the task or reschedule it on a better‑suited resource.
The framework is built with modularity and interoperability in mind. Sensors are implemented in C++ and communicate via ZeroMQ; the local manager uses Python with Pandas and Scikit‑learn; the global components are Java services exposing both RESTful and gRPC interfaces, allowing seamless integration with existing Grid middleware. Deployment is containerized using Docker and orchestrated with Kubernetes, making the solution applicable to both cloud‑based and on‑premises clusters.
Experimental evaluation comprises two scenarios. In a large‑scale simulation of a 1,000‑node Grid with synthetic workloads that exhibit abrupt load changes, the framework’s automatic tuning and migration reduced average response time by over 30 % and increased overall throughput by roughly 25 %. In a real‑world test on a 200‑node university research cluster running a scientific simulation, the system met a 5‑second response‑time SLA in 92 % of runs, cut QoS violation rates by more than 40 % compared to a baseline, and achieved an average 12 % reduction in power consumption. These results demonstrate that real‑time performance analysis combined with adaptive tuning and resource brokering can substantially improve QoS adherence and resource efficiency in Grid environments.
The authors acknowledge current limitations, such as limited support for accelerator resources (GPUs, FPGAs) and the computational overhead of the policy engine. Future work will extend the framework to heterogeneous accelerators, incorporate reinforcement‑learning‑based policy generation, and explore blockchain‑based mechanisms for trustworthy resource accounting. The paper concludes that an integrated, real‑time performance management approach is essential for sustaining desired QoS in the ever‑changing landscape of Grid computing.
Comments & Academic Discussion
Loading comments...
Leave a Comment