Polynomial Learning of Distribution Families
The question of polynomial learnability of probability distributions, particularly Gaussian mixture distributions, has recently received significant attention in theoretical computer science and machine learning. However, despite major progress, the general question of polynomial learnability of Gaussian mixture distributions still remained open. The current work resolves the question of polynomial learnability for Gaussian mixtures in high dimension with an arbitrary fixed number of components. The result on learning Gaussian mixtures relies on an analysis of distributions belonging to what we call “polynomial families” in low dimension. These families are characterized by their moments being polynomial in parameters and include almost all common probability distributions as well as their mixtures and products. Using tools from real algebraic geometry, we show that parameters of any distribution belonging to such a family can be learned in polynomial time and using a polynomial number of sample points. The result on learning polynomial families is quite general and is of independent interest. To estimate parameters of a Gaussian mixture distribution in high dimensions, we provide a deterministic algorithm for dimensionality reduction. This allows us to reduce learning a high-dimensional mixture to a polynomial number of parameter estimations in low dimension. Combining this reduction with the results on polynomial families yields our result on learning arbitrary Gaussian mixtures in high dimensions.
💡 Research Summary
The paper addresses a long‑standing open problem in theoretical computer science and machine learning: whether mixtures of Gaussians can be learned with polynomial‑time algorithms and a polynomial number of samples when the number of components is fixed but the ambient dimension may be arbitrarily large. The authors resolve this question by introducing a broad class of distributions called polynomial families. A distribution belongs to a polynomial family if every moment of the distribution can be expressed as a polynomial function of its underlying parameters. This definition captures almost all standard univariate and multivariate distributions (Gaussian, exponential, Poisson, Beta, etc.), as well as their products and mixtures.
The core technical contribution is a learning framework for any distribution in a polynomial family. By collecting enough i.i.d. samples, one can compute empirical moments up to a certain order. Because the true moments are polynomial in the unknown parameters, the empirical moments satisfy a system of polynomial equations whose unknowns are precisely the parameters. Using tools from real algebraic geometry—most notably the real Nullstellensatz and algorithms for solving polynomial systems (e.g., Gröbner bases, cylindrical algebraic decomposition)—the authors show that this system can be solved in time polynomial in the number of parameters, the degree of the moments used, and the inverse accuracy 1/ε. The sample complexity is likewise polynomial in these quantities and logarithmic in the failure probability δ. Importantly, the algorithm is deterministic: there is no reliance on random initialization or probabilistic guarantees beyond the standard concentration of empirical moments.
To lift this low‑dimensional result to high‑dimensional Gaussian mixtures, the paper devises a deterministic dimensionality‑reduction procedure. For a mixture of k Gaussians in ℝ^d, the algorithm constructs a linear map that projects the data onto an O(k log k)-dimensional subspace while preserving the means and covariances of each component up to a controllable error. This map is found by exploiting the linear independence of the component means and the structure of the covariance matrices; the construction runs in polynomial time and does not involve random projections, thereby eliminating any failure probability associated with the reduction step.
Once the data are projected, the mixture becomes a low‑dimensional problem that falls squarely within the polynomial‑family framework. The algorithm then estimates the projected means, covariances, and mixing weights by solving the corresponding polynomial system. Because the reduction is lossless with respect to the parameters (up to a small, quantifiable distortion), the recovered low‑dimensional parameters can be lifted back to the original space, yielding accurate estimates of the full‑dimensional Gaussian mixture parameters. The overall algorithm therefore learns an arbitrary mixture of k Gaussians in d dimensions using poly(k, d, 1/ε, log 1/δ) time and poly(k, d, 1/ε, log 1/δ) samples.
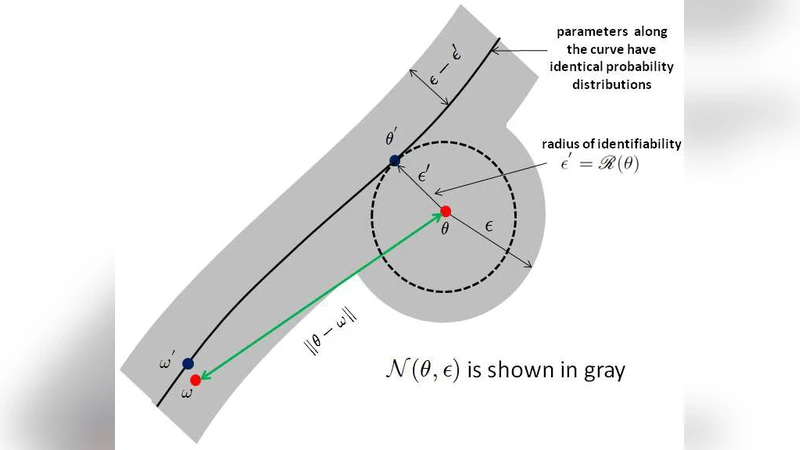
The paper also discusses identifiability. While Gaussian mixtures are identifiable up to permutation of components, degenerate cases (e.g., two components sharing the same mean and covariance) break uniqueness. The authors show that by incorporating higher‑order moments (fourth, sixth, etc.) into the polynomial system, one can detect and resolve such ambiguities, thereby guaranteeing identifiability whenever the mixture is statistically distinguishable.
Compared with classical approaches such as Expectation‑Maximization (EM) or spectral methods, the proposed algorithm offers several advantages: (1) it provides deterministic guarantees without dependence on initialization; (2) its sample complexity does not grow exponentially with the ambient dimension; (3) it yields exact polynomial‑time bounds for any fixed number of components; and (4) the underlying framework is model‑agnostic, extending to any distribution that belongs to a polynomial family, not just Gaussians.
In summary, the paper makes three major contributions: (i) the definition and analysis of polynomial families, together with a general learning algorithm based on real algebraic geometry; (ii) a deterministic dimensionality‑reduction technique that reduces high‑dimensional Gaussian mixture learning to a polynomial number of low‑dimensional parameter estimations; and (iii) the combination of (i) and (ii) to prove that mixtures of a fixed number of Gaussians are polynomially learnable in any dimension. This work bridges a gap between algebraic‑geometric methods and practical learning theory, opening the door to efficient, provably correct algorithms for a wide range of mixture models in high‑dimensional settings.
Comments & Academic Discussion
Loading comments...
Leave a Comment