Given a directed acyclic graph with labeled vertices, we consider the problem of finding the most common label sequences ("traces") among all paths in the graph (of some maximum length m). Since the number of paths can be huge, we propose novel algorithms whose time complexity depends only on the size of the graph, and on the relative frequency epsilon of the most frequent traces. In addition, we apply techniques from streaming algorithms to achieve space usage that depends only on epsilon, and not on the number of distinct traces. The abstract problem considered models a variety of tasks concerning finding frequent patterns in event sequences. Our motivation comes from working with a data set of 2 million RFID readings from baggage trolleys at Copenhagen Airport. The question of finding frequent passenger movement patterns is mapped to the above problem. We report on experimental findings for this data set.
Deep Dive into On Finding Frequent Patterns in Directed Acyclic Graphs.
Given a directed acyclic graph with labeled vertices, we consider the problem of finding the most common label sequences (“traces”) among all paths in the graph (of some maximum length m). Since the number of paths can be huge, we propose novel algorithms whose time complexity depends only on the size of the graph, and on the relative frequency epsilon of the most frequent traces. In addition, we apply techniques from streaming algorithms to achieve space usage that depends only on epsilon, and not on the number of distinct traces. The abstract problem considered models a variety of tasks concerning finding frequent patterns in event sequences. Our motivation comes from working with a data set of 2 million RFID readings from baggage trolleys at Copenhagen Airport. The question of finding frequent passenger movement patterns is mapped to the above problem. We report on experimental findings for this data set.
Sequential pattern mining has attracted a lot of interest in recent years. However, some of the probabilistic techniques that have proven their efficiency in mining of frequent itemsets have, to our best knowledge, not been transferred to the realm of sequence mining. The aim of this paper is to take a step in that direction, namely, we propose an analogue of Toivonen's sampling-based algorithm for frequent itemset mining [15] in the context of sequential patterns.
At a conceptual level we work with a new, simple formulation of the problem: The input is a directed acyclic graph (DAG) where the vertices are events and there is an edge between two events if they are considered to be connected (i.e., part of the same event sequences). Vertices are labeled by the type of event they represent. This allows certain flexibility in modeling that is lacking in many other formulations:
• Spatio-temporal events can be connected based on both spatial and temporal closeness.
• Events that have an associated time range (rather than a single time stamp) can be connected based on an arbitrary closeness criterion.
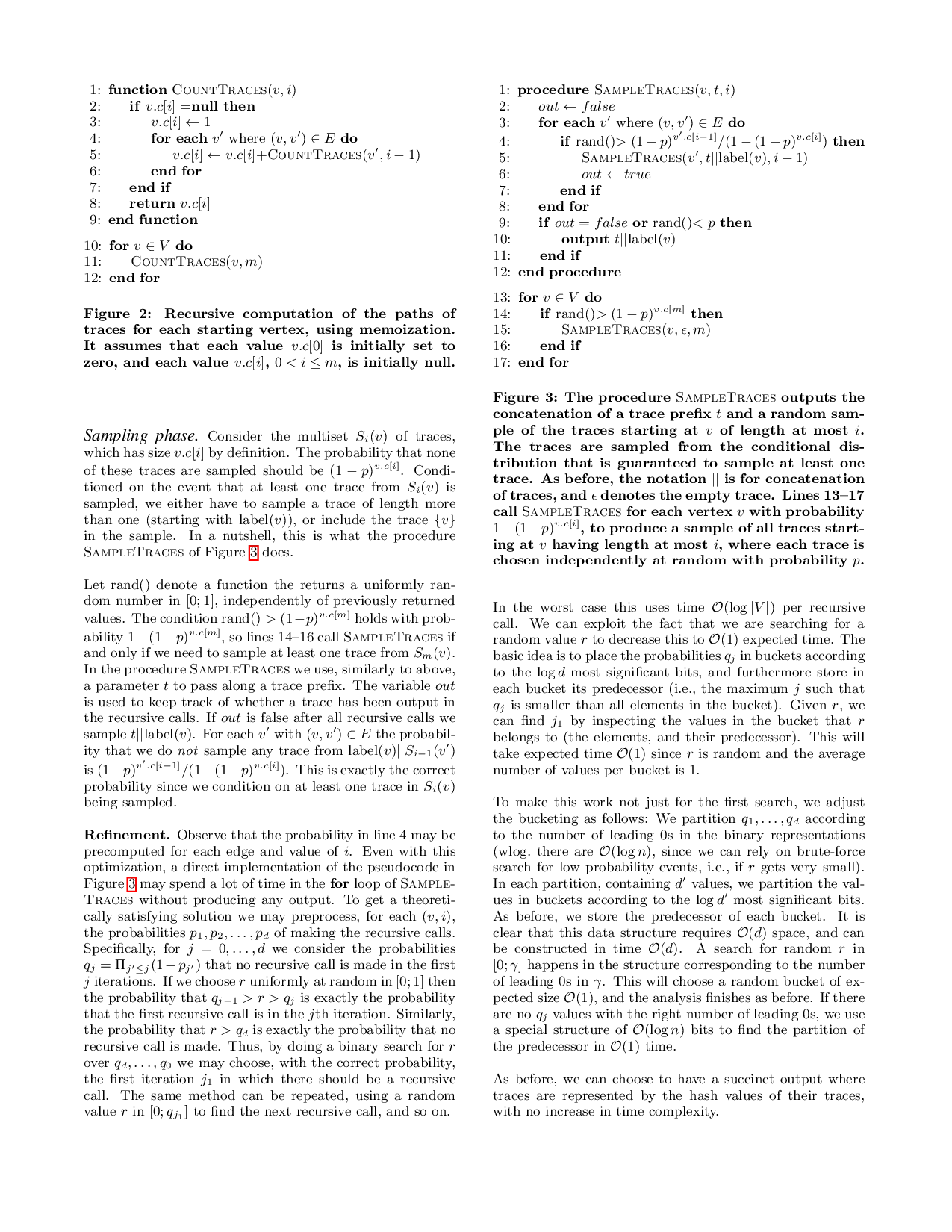
The data mining task we consider is to find the most common sequences of event types (“traces”) among all paths in the DAG, or more generally all paths of some maximum length m. The challenge is to handle the huge number of paths that may be present in a DAG. Our approach rests on a novel sampling procedure that is able to create a sample of any desired size, in time that is linear in the size of the DAG (for preprocessing) and the size of the sample (for sampling). This allows a time complexity for the mining procedure that depends on the relative frequency ε of the most common traces rather than the total number of traces. We also apply a technique from data streaming algorithms to achieve space that depends on ε rather than on the number of distinct traces.
Though our formulation does not capture all the many aspects present in other approaches to sequential pattern mining, we believe that it possesses an attractive combination of expressive modeling and algorithmic tractability.
We are given a directed acyclic graph G = (V, E), and a function label: V → L that maps vertices to their labels. A path p in G is a sequence of vertices v1, v2, . . . , vj ∈ V such that (vi, vi+1) ∈ E for i = 1, . . . , j -1. A path p has a trace label(p), which is the vector of labels on the path. Let Sm denote the multiset of all path traces of length at most m, i.e.,
The data mining task is to find the most frequent traces in Sm. It comes in several flavors:
• Top-k. For a parameter k, find the k traces that have the most occurrences in Sm (breaking ties arbitrarily).
• Frequency ε. Find the set of traces that have relative frequency ε or more in Sm.
• Monte Carlo. For both the above variants we can allow an error probability δ (typically allowing a false negative probability, i.e., that we fail to report a trace with probability δ).
In this paper emphasis will be on Monte Carlo algorithms for the frequency variant. However, we note one can also obtain results for top-k by a simple reduction.
There is a large body of related work on sequence data mining, see e.g. [12,14,8,6,18,5,2,13]. These works deviate from the present one in that they consider the input as a sequence of timestamped events, and allow a host of formulations of what kinds of subsequences are of interest. In contrast, we put the modeling of interesting subsequences into the description of the event sequence (by defining DAG edges), and the patterns sought are simple strings. This allows us to do things that we believe have not been done, and are probably difficult, in traditional sequential data mining settings, namely making use of sampling methods. The difficulty with sampling is, of course, that patterns can overlap in complicated ways, so any straightforward approach (such as sampling nodes or edges) will fail to give independent samples.
Another related area is algorithms for finding frequent subgraphs in graphs, see e.g. [17,7,11,4]. Indeed, the problem we consider can be seen as that of finding frequent (labeled) paths in an acyclic graph. Our work deviates from previous works mainly in that we consider directed acyclic graphs rather than general (undirected) graphs. This allows us to present algorithms with provable upper bounds on space usage and running time. No such efficient bounds are possible for general graphs: Even the problem of determining if a graph contains a simple path of length k requires time exponential in k [1,16], and this is inevitable assuming the hamilton cycle problem requires exponential time in the number of vertices (a well-established hypothesis). In addition, we believe that this is the first use of sampling methods in the context of finding frequent subgraphs. Possibly, this could inspire further work on using sampling in graph mining.
As a warmup we consider the task of producing the multiset of all traces having m
…(Full text truncated)…
This content is AI-processed based on ArXiv data.