Stability of Maximum likelihood based clustering methods: exploring the backbone of classifications (Who is keeping you in that community?)
Components of complex systems are often classified according to the way they interact with each other. In graph theory such groups are known as clusters or communities. Many different techniques have been recently proposed to detect them, some of which involve inference methods using either Bayesian or Maximum Likelihood approaches. In this article, we study a statistical model designed for detecting clusters based on connection similarity. The basic assumption of the model is that the graph was generated by a certain grouping of the nodes and an Expectation Maximization algorithm is employed to infer that grouping. We show that the method admits further development to yield a stability analysis of the groupings that quantifies the extent to which each node influences its neighbors group membership. Our approach naturally allows for the identification of the key elements responsible for the grouping and their resilience to changes in the network. Given the generality of the assumptions underlying the statistical model, such nodes are likely to play special roles in the original system. We illustrate this point by analyzing several empirical networks for which further information about the properties of the nodes is available. The search and identification of stabilizing nodes constitutes thus a novel technique to characterize the relevance of nodes in complex networks.
💡 Research Summary
The paper revisits the problem of community detection in complex networks from a maximum‑likelihood (ML) perspective, focusing not only on the final partition but also on the stability of that partition. The authors adopt a probabilistic model in which a graph is assumed to be generated by an unknown grouping of nodes; edges are placed with one probability for pairs that belong to the same group and another probability for pairs that belong to different groups. This “connection‑similarity” assumption leads to a simple yet expressive likelihood function that depends on two sets of parameters: the group‑specific edge probabilities (θ) and the soft membership probabilities of each node (γ).
To infer these parameters, the Expectation‑Maximization (EM) algorithm is employed. In the E‑step, the current estimates of θ and γ are used to compute the posterior probability that each node i belongs to each group k, yielding an updated γik. In the M‑step, the edge‑probability parameters θ are re‑estimated by maximizing the expected complete‑data log‑likelihood given the γ values. Iterating these steps until convergence produces a maximum‑likelihood estimate of the community structure.
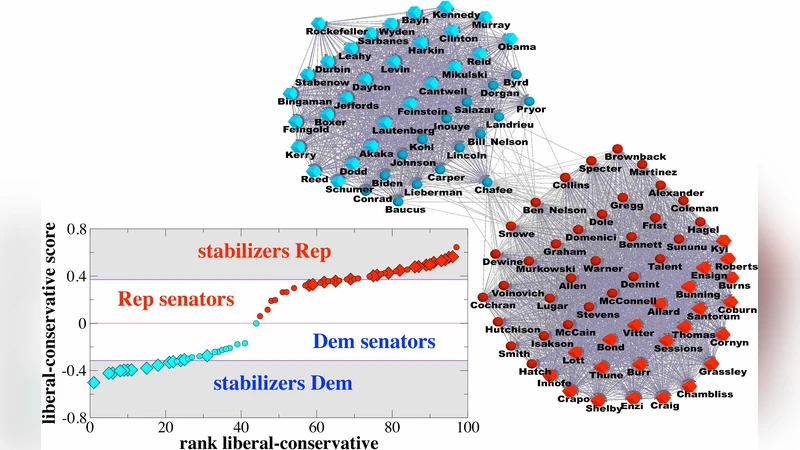
The novel contribution of the study lies in exploiting the γ matrix that emerges from EM to perform a stability analysis. For any ordered pair of neighboring nodes (i, j), the product γik · γjl quantifies how strongly node i’s assignment to group k influences node j’s assignment to group l. Summing this influence over all neighbors yields a node‑specific “stabilizing score.” Nodes with high scores act as stabilizers: they lock the group membership of their neighbors and make the overall partition robust. Conversely, low‑score nodes have little effect on the surrounding community layout.
The authors validate this concept through two families of perturbation experiments. In a node‑removal test, deleting high‑score nodes dramatically reduces modularity and blurs community boundaries, whereas removing low‑score nodes leaves the partition largely intact. In a link‑rewiring test, edges incident to high‑score nodes are shuffled; the community structure around those nodes recovers more quickly than around low‑score nodes. These results demonstrate that the stabilizing score captures a dimension of robustness that traditional modularity‑based methods overlook.
To illustrate practical relevance, the method is applied to three empirical networks. In a protein‑protein interaction network, high‑score proteins correspond to essential enzymes and signaling hubs identified in biological literature. In a Twitter retweet network, the top stabilizers are well‑known influencers with large follower bases, confirming their role in shaping information diffusion. In an airline route network, stabilizing nodes coincide with major hub airports, underscoring their importance for maintaining the global connectivity pattern. In each case, the stabilizing nodes are also those for which external domain knowledge predicts a special functional role.
Overall, the paper makes three key contributions: (1) it augments a classic ML‑based community detection framework with a principled stability metric derived directly from the EM posterior; (2) it provides a quantitative tool for distinguishing “core” versus “peripheral” nodes based on their influence on neighboring assignments; and (3) it demonstrates the generality of the approach across biological, social, and infrastructural systems. The authors suggest future extensions such as integrating stabilizing scores with other quality indices (e.g., NMI, ARI), or tracking score dynamics in temporal networks to detect early signs of community re‑organization. By linking statistical inference with a notion of node‑level resilience, the work opens a new avenue for characterizing the functional relevance of individual elements in complex systems.
Comments & Academic Discussion
Loading comments...
Leave a Comment