State Of The Art In Digital Steganography Focusing ASCII Text Documents
Digitization of analogue signals has opened up new avenues for information hiding and the recent advancements in the telecommunication field has taken up this desire even further. From copper wire to fiber optics, technology has evolved and so are ways of covert channel communication. By “Covert” we mean “anything not meant for the purpose for which it is being used”. Investigation and detection of existence of such cover channel communication has always remained a serious concern of information security professionals which has now been evolved into a motivating source of an adversary to communicate secretly in “open” without being allegedly caught or noticed. This paper presents a survey report on steganographic techniques which have been evolved over the years to hide the existence of secret information inside some cover (Text) object. The introduction of the subject is followed by the discussion which is narrowed down to the area where digital ASCII Text documents are being used as cover. Finally, the conclusion sums up the proceedings.
💡 Research Summary
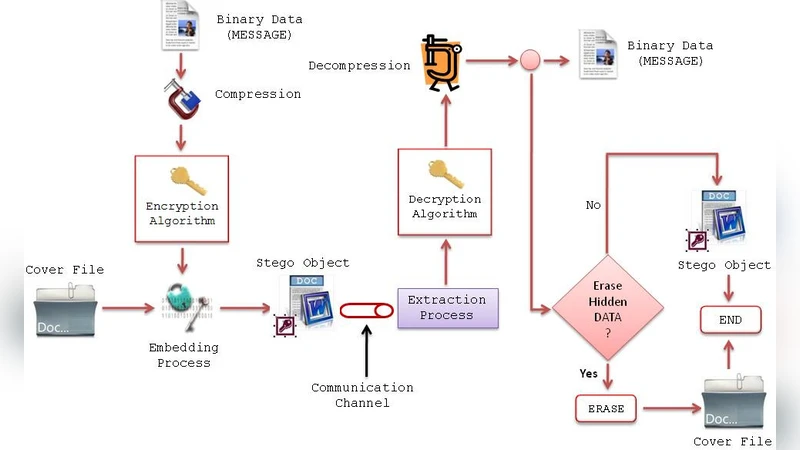
The paper presents a comprehensive survey of digital steganography techniques that use ASCII text documents as cover media. Beginning with an introduction that distinguishes steganography from cryptography, the authors define “covert channel” as any communication path not intended for the transmitted data, emphasizing its relevance in modern information security. Terminology is clarified: the cover text, stego‑text, and stego‑key are introduced, and the embedding and extraction processes are mathematically modeled using functions η (embedding) and Ȩ (extraction). The model follows a three‑step pipeline: compression of the secret message, encryption with a symmetric key, and embedding of the encrypted payload into the cover using the stego‑key.
The survey categorizes steganographic methods into linguistic (syntactic and semantic) and technical approaches. Linguistic techniques exploit natural language properties such as acrostics, synonyms, spelling variations, and acronyms. Technical techniques include substitution, transformation (e.g., frequency‑domain embedding), spread‑spectrum, statistical alteration, distortion, and cover generation. Each class is discussed with its advantages, limitations, and typical application domains.
Three types of steganographic systems are outlined: Pure Steganography (no secret key, relying on secrecy of the method), Secret‑Key Steganography (shared stego‑key between sender and receiver), and Public‑Key Steganography (asymmetric key pair). The paper notes that pure systems are the weakest, while public‑key schemes offer better key management at the cost of higher complexity.
The authors then enumerate a wide range of embedding applications, ranging from non‑repudiation and integrity verification to copyright protection, database annotation, device control, in‑band signaling, trailer tracing, and media forensics. They argue that the proliferation of Internet and intranet services has created many opportunities for covert data hiding.
In the “Related Work” section, specific text‑based hiding techniques are examined in detail. The acronym method replaces selected words with their abbreviations according to a predefined mapping table, encoding bits as 0 or 1. The spelling‑variation method uses British versus American spellings to represent bits, while the semantic method substitutes a word with its synonym based on a similar binary mapping. Miscellaneous techniques include intentional typographical errors, transliterations (e.g., “gr8”), irregular line breaks, emoticons, and colloquial expressions. All these approaches share the characteristic of being rule‑based and relatively easy to implement, but they suffer from low security because an adversary who knows the mapping can readily recover the hidden data, violating Kerckhoffs’s principle.
Steganalysis models are briefly described: a blind detection model that operates without prior knowledge of the embedding algorithm, and an analytical model that leverages known attributes of the stego‑object (format, type, statistical features) to guide extraction. The paper points out that most existing detection techniques are statistical or machine‑learning based, yet the surveyed text steganography methods have not been extensively evaluated against modern steganalysis tools.
The authors conclude that while text steganography offers the advantage of requiring no special hardware and being largely invisible to human readers, its limited capacity and vulnerability to simple statistical attacks remain significant challenges. They recommend future research directions such as integrating natural language generation models (e.g., GPT‑style transformers) to produce dynamic, context‑aware cover texts, developing large‑scale corpora for automated synonym/acronym mapping, and designing robust statistical counter‑measures to evade detection. Overall, the paper provides a solid foundational overview of ASCII‑text steganography, highlights its practical applications, and identifies gaps that need to be addressed for the field to mature.
Comments & Academic Discussion
Loading comments...
Leave a Comment