Statistical significance of communities in networks
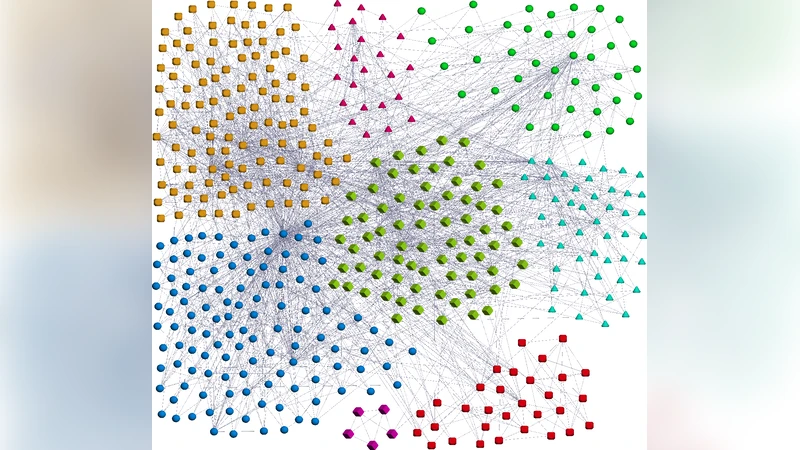
Nodes in real-world networks are usually organized in local modules. These groups, called communities, are intuitively defined as sub-graphs with a larger density of internal connections than of external links. In this work, we introduce a new measure aimed at quantifying the statistical significance of single communities. Extreme and Order Statistics are used to predict the statistics associated with individual clusters in random graphs. These distributions allows us to define one community significance as the probability that a generic clustering algorithm finds such a group in a random graph. The method is successfully applied in the case of real-world networks for the evaluation of the significance of their communities.
💡 Research Summary
The paper addresses a fundamental gap in network science: while many algorithms can detect densely connected groups of nodes (communities), there is no widely accepted statistical test to determine whether a discovered community is genuinely significant or could have arisen by chance in a random graph. To fill this gap, the authors propose a rigorous statistical framework that quantifies the significance of individual communities using concepts from Extreme Value Theory (EVT) and Order Statistics.
Core Idea
The authors treat a community as a subgraph characterized by two parameters: its size (s) (the number of nodes) and its internal edge count (k). Under a chosen null model—typically an Erdős–Rényi random graph or a degree‑preserving configuration model—they derive the probability that a random subgraph of size (s) would have at least (k) internal edges. Because directly computing the tail probability for large (k) is intractable, they approximate the distribution of the maximum internal edge count across all possible subgraphs of size (s) using EVT. This yields a closed‑form expression (often a Gumbel or Weibull CDF) that serves as a p‑value for the community: the smaller the p‑value, the less likely the community could be produced by chance.
Multiple‑Testing Correction
When a clustering algorithm returns many communities, testing each one independently inflates the false‑positive rate. To address this, the authors employ Order Statistics: they model the distribution of the smallest p‑value among (N) independent tests and compute the probability that the observed minimum could arise under the null model. This provides a global significance assessment for the entire partition, complementing the local test for each community.
Algorithmic Workflow
- Run any standard community detection method (e.g., Louvain, Infomap) to obtain a set of candidate communities.
- For each community, compute its size (s) and internal edge count (k).
- Using the selected null model, calculate the EVT‑based p‑value (p(C)).
- Compare (p(C)) to a pre‑defined significance threshold (commonly 0.05) to decide whether the community is statistically significant.
- Apply the Order‑Statistics correction to the collection of p‑values to evaluate the overall significance of the clustering result.
Empirical Validation
The authors test the framework on both synthetic and real‑world networks. Synthetic experiments use planted‑partition graphs where ground‑truth communities are known. The method reliably identifies the planted groups (high recall) while maintaining a low false‑positive rate, confirming that the EVT approximation is accurate for the regimes examined. Real‑world case studies include political blog networks, protein‑protein interaction maps, and Internet autonomous system (AS) graphs. In most cases, communities previously reported in the literature receive low p‑values (often <0.01), supporting their substantive relevance. Conversely, some previously highlighted groups turn out to be statistically indistinguishable from random fluctuations (p‑values >0.2), illustrating the method’s ability to flag over‑interpreted structures.
Key Contributions
- Formal Definition of Community Significance – Provides a clear probabilistic interpretation of what it means for a community to be “significant.”
- Application of Extreme Value Theory – Introduces EVT to network analysis, enabling tractable tail‑probability estimates for dense subgraphs.
- Order‑Statistics Based Global Test – Offers a principled way to control for multiple testing when evaluating an entire clustering output.
- Model‑Agnostic Post‑Processing – The framework can be applied as a post‑hoc validation step to any existing community detection algorithm.
Limitations and Future Directions
The approach depends heavily on the choice of null model; different random graph ensembles can yield markedly different p‑values. The EVT approximation may lose accuracy for extremely large communities where the underlying assumptions (independence of subgraph edge counts) are violated. The current formulation handles only unweighted, undirected graphs; extending it to weighted or directed networks, as well as incorporating more sophisticated null models (e.g., stochastic block models with degree correction), are promising avenues. Additionally, integrating the significance test directly into the community detection process (rather than as a post‑hoc step) could improve both computational efficiency and detection quality.
Conclusion
By marrying Extreme Value Theory with Order Statistics, the paper delivers a robust, mathematically grounded method for assessing the statistical significance of individual communities and entire partitions. The framework not only helps researchers avoid spurious claims about network modularity but also provides a valuable diagnostic tool for comparing and refining community detection algorithms across diverse domains.
Comments & Academic Discussion
Loading comments...
Leave a Comment