A Minimum Relative Entropy Principle for Learning and Acting
This paper proposes a method to construct an adaptive agent that is universal with respect to a given class of experts, where each expert is an agent that has been designed specifically for a particular environment. This adaptive control problem is f…
Authors: Pedro A. Ortega, Daniel A. Braun
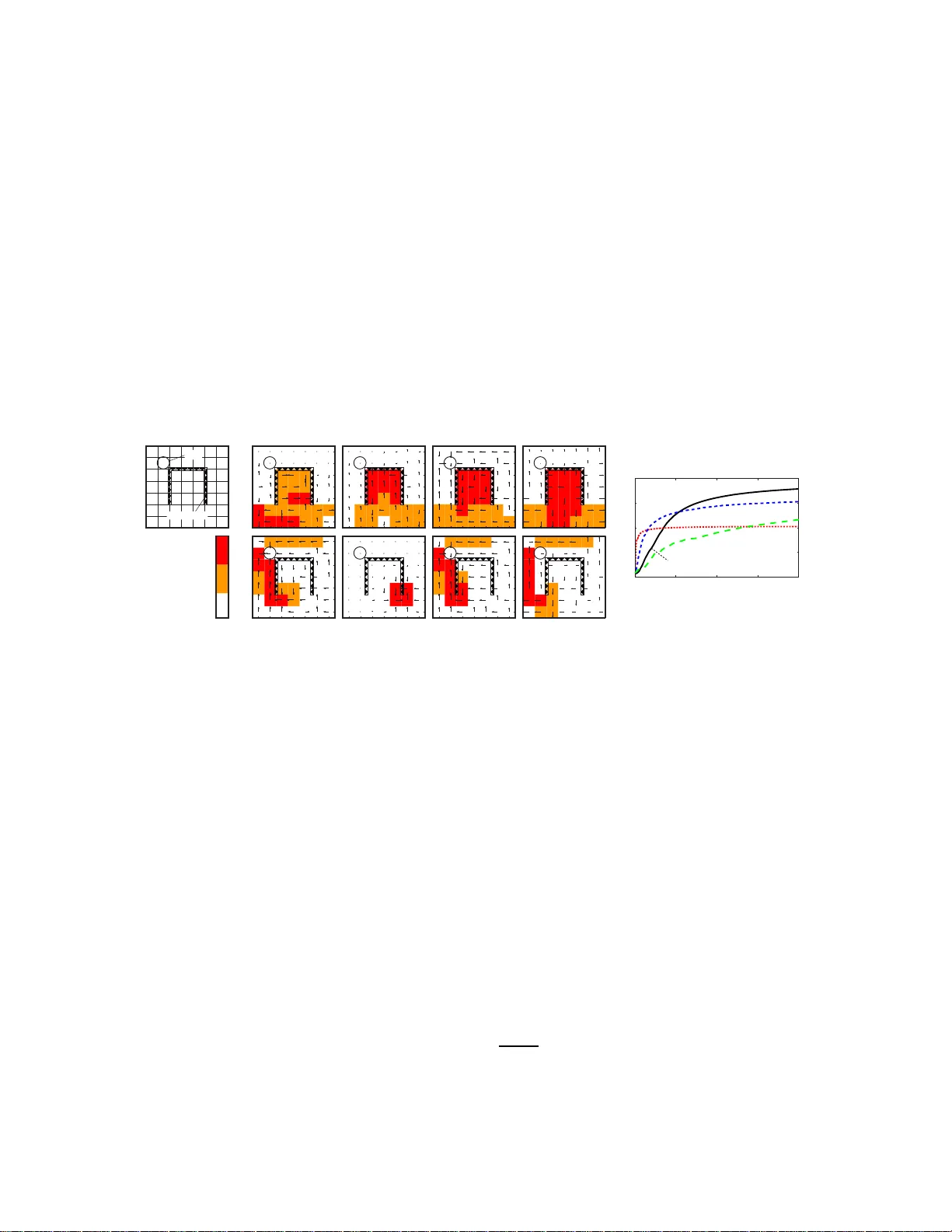
A Minimum Rela tive Entropy Principle f or Learning and Acting A Minim um Relativ e Ent rop y P rinciple for Learning and A cting P e dro A. Ortega peor tega@dcc.uchile.cl Dep artment of E ngine ering University o f Cambridge Cambridge CB 2 1PZ, UK Daniel A. Braun dab54@cam.a c.uk Dep artment of E ngine ering University o f Cambridge Cambridge CB 2 1PZ, UK Editor: — Abstract This pap er prop oses a method to construct an adaptive agent that is universal with resp ect to a given class of exp erts, where each expe r t is an agent that has been designed specifica lly for a particular en v ir onment. This adaptive control problem is for ma lized a s the problem of minimizing the relative e ntropy of the ada ptive agent from the exp ert that is most suitable for the unkno wn en vironment. If the a gent is a passive observer, then the optimal solution is the w ell-known Bay esian predictor. How ever, if the agent is a ctive, then its past actions need to b e treated a s causa l interven tio ns on the I/O stream ra ther than nor mal probability conditions . Here it is s hown that the solution to this new v aria tio nal pro blem is given b y a sto chastic controller called the Bay esian control rule, which implemen ts adaptive behavior as a mixture of exp erts. F urthermore, it is shown that under mild a s sumptions, the Bayesian co nt rol rule conv er ges to the control law of the most suitable expe rt. Keyw ords: Artificial Intelligence, Minimum Relative Entrop y P rinciple, Bay esian Con- trol Rule, In teractio n Sequences, Op er ation Mo des. 1. In t ro duction When the b eha vior of an en vironment under an y con trol signal is fully kno wn, then the designer can c ho ose an agen t 1 that pro duces the desired dynamics. In stances of this problem include h itting a target with a cannon under kn o wn weather conditions, solvi ng a maze ha ving its map and con trolling a r ob otic arm in a m an ufacturing plant. Ho wev er, when the b eha vior of the plan t is unkn o w n, th en the designer fa ces the problem of ada ptive c ontr ol . F or example, sho oting the cannon lac king the appropr iate measuremen t equipment, finding the wa y out of an un kno wn maze and designin g an autonomous rob ot f or Martia n exploration. Ad ap tive con tr ol turns out to b e far more difficult than its non-adaptive coun terpart. This is b ecause any go o d p olicy has to carefully trad e off explorativ e v ersus exploitativ e actions, i.e. actions for the iden tification of the en vironment ’s dynamics versus 1. In accordance with th e control literature, w e use the terms agent a nd c ontr ol ler in terchangeably . Simi- larly , the terms envir onment and plant are used synonymously . 1 Or tega and Braun actions to con trol it in a desired w a y . Ev en when the en vironmen t’s dynamics are kno wn to b elong to a particular class for whic h optimal agen ts are av ailable, constru cting the corresp ondin g optimal adaptive agen t is in general compu tationally in tractable ev en f or simple to y p roblems (Duff, 200 2 ). Thus, fi nding tractable appro ximations has b een a ma jor fo cus of researc h . Recen tly , it has b een prop osed to reformulate the problem statemen t for some classes of con trol pr oblems based on the minimization of a relativ e en trop y criterion. F or example, a large class of optimal control prob lems can b e solv ed ve ry efficien tly if the problem s tatemen t is reformulated as the minimization of the deviation of the dy n amics of a con trolled s y s tem from the u n con trolled s ystem (T o doro v, 2006, 2009; Kapp en et al., 2009). In th is w ork, a similar approac h is in tro duced. If a class of agen ts is giv en, where eac h agent solves a differen t envi ronment, then adaptiv e controll ers can b e derived fr om a minimum relativ e en trop y principle. In particular, one can construct an adaptiv e agen t that is u niv ersal with resp ect to this class by m in imizing the a v erage relativ e en trop y f rom the en vironment - sp ecific agen t. Ho wev er, this extension is not s tr aigh tforward. T here is a syntacti cal difference b et w een actions and observ ations that has to b e take n into accoun t when formulati ng the v ariational problem. More sp ecifically , actions ha v e to b e treated as interv ent ions ob eying the r u les of causalit y (P earl, 2000; Spirtes et al., 2000; Da wid , 2010). If this distinction is made, the v ariational problem has a unique solution giv en by a s to c hastic control rule called the Ba yesian con trol ru le. This con trol rule is particularly interesting b ecause it translates the adaptiv e control prob lem into an on-line in ference problem that can b e applied forwa rd in time. F urthermore, this w ork sho ws that u nder mild assump tions, the adaptive agen t con v erges to the en vironment-specific agen t. The pap er is organized as f ollo ws. Section 2 in tro duces n otation and sets up the adaptive con trol problem. Section 3 formulates adaptiv e con trol as a m inim um relativ e entrop y problem. After an initial, na ¨ ıv e approac h, the need for causal considerations is motiv ated. Then, the Ba y esian con trol ru le is deriv ed f rom a revised relativ e en trop y criterion. In Section 4, the conditions for con v ergence are examined and a p ro of is giv en. Section 5 illustrates the u sage of the Ba ye sian control rule for the m ulti-armed bandit pr oblem and the undiscounted Mark o v decision problem. S ection 6 discu sses p rop erties of the Ba yesian con trol rule and relates it to previous w ork in the literature. Section 7 concludes. 2. Preliminaries In the follo wing b oth agent and en vironment are formalized as causal mo dels o v er I/O sequences. Ag ent and en vironment are coupled to exc hange symbols follo wing a standard in teraction pr otocol ha ving discrete time, observ ation and con trol signals. The treatmen t of the dynamics are f ully p robabilistic, and in particular, b oth actions and observ ations are random v ariables, w hic h is in contrast to the d ecision-theoretic agen t f orm ulation treating only observ ations as random v ariables (Russ ell and Norvig, 2003 ). All pro ofs are pro vided in the app en d ix. Notation. A set is denoted b y a calligraphic letter lik e A . Th e wo rds set & alphab et and element & symb ol are used to mean the same thing resp ectiv ely . Strings are finite concatenati ons of symbols and se quenc es are infinite concatenations. A n denotes the set of 2 A Minimum Rela tive Entropy Principle for Learning and Acting strings of length n b ased on A , and A ∗ : = S n ≥ 0 A n is th e set of finite str ings. F urther- more, A ∞ : = { a 1 a 2 . . . | a i ∈ A for all i = 1 , 2 , . . . } is d efined as the set of one-w a y infinite sequences based on the alphab et A . T uples are written with parentheses ( a 1 , a 2 , a 3 ) or as strings a 1 a 2 a 3 . F or sub strings, th e follo wing shorthand notation is used: a string that ru ns from ind ex i to k is written as a i : k : = a i a i +1 . . . a k − 1 a k . Similarly , a ≤ i : = a 1 a 2 . . . a i is a string starting from the first index. Also, sym b ols are underlined to glue them toget her lik e ao in ao ≤ i : = a 1 o 1 a 2 o 2 . . . a i o i . The f unction log ( x ) is meant to b e tak en w .r.t. base 2, unless ind icated otherwise. In teractions. The p ossible I/O sym b ols are drawn from tw o finite sets. Let O denote th e set of inputs (observ ations) and let A denote the set of outputs (actions). Th e set Z : = A× O is the i nter action set . A string ao ≤ t or ao 0, there is a C ≥ 0, suc h that for all m ′ ∈ M , all t and all T ⊂ N t g ( m ′ ; T ) − G ( m ′ ; T ) ≤ C with pr ob ab ility ≥ 1 − δ . Figure 6 illustrates this pr op erty . Boundedn ess is the key p rop erty that is going to b e used to constru ct the results of this section. The first imp ortan t resu lt is that the p osterior probabilit y of the true inpu t-output mo d el is b ounded f rom b elo w. Theorem 2 L et the set of op er ation mo des of a c ontr ol ler b e suc h that for al l m ∈ M the diver genc e pr o c ess d t ( m ∗ k m ) is b ounde d. Then, for any δ > 0 , ther e is a λ > 0 , such that for al l t ∈ N , P ( m ∗ | ˆ ao ≤ t ) ≥ λ |M| with pr ob ability ≥ 1 − δ . 16 A Minimum Rela tive Entropy Principle for Learning and Acting P S f r a g r e p l a c e m e n t s 0 1 2 3 t d t Figure 6: If a div ergence pro cess is b oun ded, then the realizations (curve s 2 & 3) of a sub-diverge nce sta y with in a band around the mean (curve 1). 4.4 Core If one w ants to id entify the op eration m o des whose p osterior probabilities v an ish , then it is not enough to c h aracterize them as those mo d es whose h yp othesis does n ot matc h the true hyp othesis. Figure 7 illustrates this p roblem. Here, three hyp otheses along with their asso ciated p olicies are sho wn. H 1 and H 2 share the prediction m ad e for r egion A but differ in region B . Hyp othesis H 3 differs ev erywhere from the others. Assume H 1 is true. As long as w e app ly p olic y P 2 , hyp othesis H 3 will make wr ong predictions and thus its diverge nce pro cess will diverge as exp ecte d. Ho we ve r, no evidence against H 2 will b e accum ulated. It is only wh en one applies p olicy P 1 for long enough time that the con troller w ill eve ntuall y en ter r egion B and hence accum ulate coun ter-evidence for H 2 . P S f r a g r e p l a c e m e n t s H 1 P 1 H 2 P 2 H 3 P 3 A A B B Figure 7: If hyp othesis H 1 is true and agrees with H 2 on region A , then p olicy P 2 cannot disam biguate the three hypotheses. But what do es “long enough” mean? If P 1 is executed only for a s hort p erio d, then th e con troller risks not visiting the disambiguating region. Bu t un f ortunately , n either the righ t p olicy nor the right length of the p erio d to ru n it are kno wn b eforehand. Hence, an agen t needs a clev er time-allo cating strategy to test all p olici es for all finite time interv als. Th is motiv ates the follo wing defin ition. The c or e of an op eration m o de m ∗ , denoted as [ m ∗ ], is the s u bset of M con taining op eration mo des b eha vin g like m ∗ under its p olic y . More formally , an op eration mo de m / ∈ [ m ∗ ] (i.e. is not in the core) iff for an y C ≥ 0, δ , ξ > 0, there is a t 0 ∈ N , suc h that for all t ≥ t 0 , G ( m ∗ ; T ) ≥ C 17 Or tega and Braun with probability ≥ 1 − δ , where G ( m ∗ ; T ) is a sub-divergence of d t ( m ∗ k m ), and P r { τ ∈ T } ≥ ξ for all τ ∈ N t . In other words, if the agen t was to apply m ∗ ’s p olicy in eac h time step with p robabilit y at least ξ , and und er th is strategy the exp ected su b-dive rgence G ( m ∗ ; T ) of d t ( m ∗ k m ) gro w s unboun dedly , then m is not in the core of m ∗ . Note that d emanding a strictly p ositiv e probabilit y of execution in eac h time step guaran tees that the agen t w ill r un m ∗ for all p ossible fin ite time-in terv als. As the follo wing theorem sho ws, the p osterior probabilities of the op eration m o des that are n ot in the core v anish almost surely . Theorem 3 L et the set of op er ation mo des of an agent b e such that for al l m ∈ M the diver genc e pr o c ess d t ( m ∗ k m ) is b ounde d. If m / ∈ [ m ∗ ] , then P ( m | ˆ ao ≤ t ) → 0 as t → ∞ almost sur ely. 4.5 Consistency Ev en if an op eration mo de m is in the core of m ∗ , i.e. give n th at m is essentiall y ind is- tinguishable from m ∗ under m ∗ ’s con trol, it can still happ en that m ∗ and m ha v e d ifferen t p olicies. Figure 8 shows an example of this. The hyp otheses H 1 and H 2 share region A but differ in region B . In addition, b oth op eration mo des hav e their p olici es P 1 and P 2 resp ec- tiv ely confined to region A . Note that b oth op eration mo des are in the core of eac h other. Ho wev er, their p olicies are different. This m eans that it is unclear wh ether multiplexing th e p olicies in time will ever disam biguate the tw o hyp otheses. This is undesirable, as it could imp ede th e con v ergence to the right con trol la w. P S f r a g r e p l a c e m e n t s H 1 P 1 H 2 P 2 A A B B Figure 8: An examp le of inconsisten t p olicies. Both operation mo des are in the core of eac h other, bu t ha ve differen t p olicies. Th us, it is clear that one needs to imp ose fur ther restrictions on th e m apping of h y- p otheses into p olic ies. With resp ect to Figure 8 , one can make th e follo wing observ ations: 1. Both op eration mo des ha v e p olicies that select subsets of region A . Therefore, th e dynamics in A are preferr ed o ver the dynamics in B . 2. Knowing that the dynamics in A are preferred o v er th e dynamics in B allo ws u s to drop r egion B from the analysis w hen c ho osing a p olicy . 3. Since b oth h yp otheses agree in region A , they have to cho ose the same p olicy in or der to b e c onsistent i n their sele ction criterion . 18 A Minimum Rela tive Entropy Principle for Learning and Acting This motiv ates the f ollo wing defi nition. An op eration mo de m is said to b e c onsistent with m ∗ iff m ∈ [ m ∗ ] implies that for all ε < 0, ther e is a t 0 , suc h that for all t ≥ t 0 and all ao 0 are learning rates. T h e exploration strategy chooses with fixed pr obabilit y p exp > 0 the action a that maximizes Q ( x, a ) + C F ( x,a ) , where C is a constan t, and F ( x, a ) represent s the num b er of times that action a has b een tried in state x . Thus, higher v alues of C enforce increased exploration. 23 Or tega and Braun Average Rew ard BCR 0 . 3582 ± 0 . 0038 R-learning, C = 200 0 . 2314 ± 0 . 0024 R-learning, C = 30 0 . 3056 ± 0 . 0063 R-learning, C = 5 0 . 2049 ± 0 . 0012 T able 1: Av erage reward atta ined by th e d ifferen t algorithms at the end of the run. The mean and th e standard deviation h as b een calculat ed b ased on 10 runs. In Mahadev an (199 6 ), a grid-world is describ ed that is esp eciall y us eful as a test b ed for the analysis of RL algorithms. F or our purp oses, it is of particular interest b ecause it is easy to design exp eriments con taining sub optimal limit-cycles . Figure 11, panel (a), illustrates the 7 × 7 grid -w orld. A controlle r has to learn a p olicy th at leads it f rom an y initial lo cation to the goal state. A t eac h step, the agen t can mo ve to an y adjacen t space (up, down, left or righ t). If the agent reac h es the goal state then its next p osition is rand omly set to an y square of the grid (with u niform probabilit y) to start another trial. There are also “one- w a y mem branes” that allo w the agen t to mov e in to one d irection b u t not into th e other. In these exp erimen ts, these mem branes form “in ve rted cups” that the agen t can ente r from an y side but can on ly lea v e through the b ottom, pla ying the role of a lo cal maximum. T ransitions are stochastic: the agen t mov es to the correct square w ith probabilit y p = 9 10 and to an y of the free adj acent sp aces (uniform distribution) with probabilit y 1 − p = 1 10 . Rew ards are assigned as follo ws. The d efault r ew ard is r = 0. I f the agen t tra v erses a mem brane it obtains a r ew ard of r = 1. Reac hing th e goal state assigns r = 2 . 5. The parameters c hosen for this sim ulation we re th e f ollo wing. F or our MDP-agen t, w e hav e c hosen h yp erp arameters µ 0 = 1 and λ 0 = 1 and p recision p = 1. F or R-learning, we ha v e c hosen learning rates α = 0 . 5 and β = 0 . 001, and the exploration constan t has b een set to C = 5, C = 30 and to C = 200. A total of 10 runs w ere carried out for eac h algorithm. The results are p r esen ted in Figure 11 and T able 5.2. R-learning only learns the optimal p olicy giv en sufficien t exploration (p anels c & d, b otto m r o w ), wh er eas the Ba y esian con trol rule learns the p olicy successfully . In Figure 11e, the learning curve of R-learning for C = 5 and C = 30 is initially steep er than the Ba y esian con troller. How ev er, the latt er atta ins a higher a ve rage reward aroun d time step 125,000 on w ards. W e attribute this shallo w initial transien t to the p hase where the distrib u tion o v er the op eratio n mo des is flat, whic h is also reflected by the initially random exploratory b eha vior. 6. Discussion The key idea of this work is to extend the minimum relativ e en trop y prin ciple, i.e. the v ariational pr inciple u nderlying Ba yesian estimation, to the pr oblem of adap tive con trol. F rom a cod ing p oint of view, this work extends the idea of maximal compression of the observ ation stream to the whole exp erience of the agen t conta ining b oth the agen t’s actions and observ ations. This not only minimizes the amoun t of bits to write when saving/enc o ding 24 A Minimum Rela tive Entropy Principle for Learning and Acting the I/O stream, b ut it also minimizes the amoun t of bits required to pr o duc e /de c o de an action (MacKa y , 2003, Chapter 6). This extension is non-trivial, b ecause there is an imp ortant ca v eat for codin g I/O se- quences: u n lik e observ ations, acti ons do n ot carry an y information that could b e used f or inference in adaptiv e co ding b eca use actions are issued b y the deco der itself. Th e p r oblem is that d oing inf er en ce on ones o wn actions is logically inconsistent and leads to paradoxes (Nozic k , 1969). Th is seemingly inno cuous issu e has turned out to b e very in tricate and has b een inv estigated intensely in the recen t past b y researc her s fo cu sing on the issue of causalit y (P earl, 2000; Spirtes et al., 200 0; Dawid, 2010). Ou r w ork con tributes to this b o dy of researc h b y p ro viding further evidence th at actions cannot b e treated using probability calculus alone. If the causal d ep enden cies are carefully tak en into accoun t, then min im izing the relativ e en trop y leads to a r u le for adaptiv e con trol wh ich h as b een called the Ba yesian con trol r u le. This ru le allo ws combining a class of task-sp ecific agen ts into an agent that is universal with resp ect to this class. The resulting con trol law is a simple sto chasti c con trol ru le th at is completely general and p arameter-free. As the analysis in this pap er sho ws, this cont rol rule con ve rges to the tru e con trol la w under mild assumptions. 6.1 Critical issues • Causality. Virtually ev ery adaptiv e con trol metho d in the literature successfully treats actions as conditionals ov er observ ation streams and nev er wo rries ab out causalit y . Th us, why b other ab out in terv en tions? In a d ecision-theoretic setup, th e decision mak er c ho oses a p olicy π ∗ ∈ Π maximizing the exp ected utilit y U ov er the outcomes ω ∈ Ω, i.e. π ∗ : = arg max π E [ U | π ] = P ω P r ( ω | π ) U ( ω ). “Ch o osing π ∗ ” is form ally equiv alen t to choosing the Kroneck er delta fun ction δ π π ∗ as the probabilit y distribu tion o ver p olicies. In this case, the conditional probabilities P r ( ω | π ) and P r ( ω | ˆ π ) coincide, since P r ( ω , π ) = P r ( π ) P r ( ω | π ) = δ π π ∗ P r ( ω | π ) = P r ( ω , ˆ π ) . Hence, the formalization of actions as int erve ntio ns an d observ ations as conditions is p erfectly compatible with the d ecision-theoretic s etup and in fact generalizes decision v ariables to the status of in terv ened random v ariables. • Wher e do prior pr ob abilities/likeliho o d mo dels/p olicies c ome fr om? The predictor in the Ba yesia n con tr ol rule is essen tially a Ba yesia n predictor and th ereb y en tails (al- most) the same mo d eling p aradigm. The designer has to d efine a class of hyp otheses o ver the en vironm ents, construct approp r iate likeli ho o d mod els, and c ho ose a suitable prior p r obabilit y d istribution to capture the mo del’s uncertain t y . Similarly , und er suf- ficien t domain knowle dge, an analogous pr o cedure can b e applied to construct suitable op eration mo des. Ho w ev er, there are man y situations where this is a d iffi cu lt or even in tractable p roblem in itself. F or example, one can design a class of op er ation m o des b y pr e-computing th e optimal p olicies for a giv en class of en vironments. F ormally , let Θ b e a cla ss of h yp otheses mo deling en vironment s and let Π b e class of p olicies. Giv en a utilit y criterion U , define the set of op eration mo des M : = { m θ } θ ∈ Θ b y construct- ing eac h op eration m o de as m θ : = ( θ , π ∗ ), π ∗ ∈ π , where π ∗ : = arg max π E [ U | θ , π ]. 25 Or tega and Braun Ho wev er, computing the optimal p olicy π ∗ is in many cases intrac table. In some cases, this can b e remedied b y c haracterizing the op eration mo d es through optimalit y equations whic h are solved b y probabilistic inference as in the example of the MDP agen t in Sectio n 5.2. Recen tly , w e ha v e applied a similar app roac h to ad ap tive control problems with linear quadratic regulators (Ortega and Braun, 2010b ). • Pr oblems of Bayesian metho ds. The Ba y esian control r ule treats an adaptive con trol problem as a Ba yesia n in ference problem. Hence, all the problems t ypically associated with Ba y esian metho ds carry ov er to agen ts constr u cted with th e Ba yesia n cont rol rule. These problems are of b oth analytical and computational natur e. F or examp le, there are m an y pr obabilistic mo dels wh er e the p osterior distribution do es not hav e a closed-form s olution. Also, exact probab ilistic inference is in general computationally v ery inte nsive. Even th ough there is a large literature in efficien t/appro ximate inf er- ence algorithms for p articular problem classes (Bishop, 2006), n ot m any of them are suitable for on-line p robabilistic inference in m ore realistic en vironment classes. • Bayesian c ontr ol rule versus Bayes-optimal c ontr ol. Directly maximizing th e (sub jec- tiv e) exp ected utilit y for a giv en en vironment class is n ot the same as minimizing the exp ected relativ e en tropy for a give n class of op eration mo des. As suc h, the Ba y esian con trol rule is not a Ba yes-o ptimal con troller. Indeed, it is easy to design exp eriment s where the Ba y esian control rule con v erges exp onen tially slo w er (or d o es not con v erge at all) than a Ba y es-optimal con troller to the maxim um utilit y . C onsider the follo wing simple example: En vironment 1 is a k -state MDP in whic h only k consecutive actions A reac h a s tate with reward +1. Any int erception with a B -actio n leads bac k to the initial state. Consider a second envi ronment whic h is lik e th e fir st but actions A and B are in terc hanged. A Ba y es-optimal control ler fi gu r es out the true envi ronment in k actions (either k consecutiv e A ’s or B ’s). Cons ider no w the Ba y esian con trol rule: The optimal action in Environmen t 1 is A , in Environmen t 2 is B . A uniform ( 1 2 , 1 2 ) prior o ver the op eration mo des stays a uniform p osterior as long as no rewa rd has b een observ ed. Hence th e Ba yesia n con trol rule c h o oses at eac h time-step A and B with equal pr obabilit y . With this p olicy it tak es ab out 2 k actions to acciden tally choose a ro w of A ’s (or B ’s) of length k . F rom then on the Ba yesia n control rule is optimal to o. S o a Ba ye s-optimal con troller conv erges in time k , while the Ba y esian cont rol rule n eeds exp onentiall y longer. One wa y to r emedy this p roblem might b e to allo w the Ba y esian cont rol rule to sample actions from the same op eration mo de for sev eral time steps in a ro w rather than rand omizing con trollers in every cycle. Ho wev er, if one considers non-stationary envi ronments this str ategy can also br eak do w n. Con- sider, for example, an increasing MDP with k = 10 √ t , in whic h a Ba y es-optimal con troller conv erges in 100 steps, while the Ba y esian con trol r ule do es not conv erge at all in most realizatio ns, b ecause the b ound edness assumption is violated. 6.2 Relation to existing approac hes Some of the ideas under lyin g this w ork are not unique to the Ba y esian con trol rule. The follo win g is a selection of previously pu blished w ork in the recen t Ba yesia n reinforcement learning literature where r elated ideas can b e found. 26 A Minimum Rela tive Entropy Principle for Learning and Acting • Compr ession principles. In the literature, there is an imp ortant amoun t of w ork relating compression to intel ligence (MacKa y , 2003; Hutter, 2004a ). In particular, it has b een ev en prop osed that compression ratio is an ob jectiv e qu antitat iv e m easure of in telligence (Mahoney, 1999). Compression has also b een used as a b asis for a theory of cur iosity , creativit y and b eaut y (Schmidh ub er , 2009). • Mixtur e of exp erts. Pa ssive sequence p r ediction b y m ixing exp erts h as b een stud - ied extensive ly in the literature (Cesa-Bianc hi and Lugosi, 2006). In (Hutter , 2004b), Ba yes-o ptimal p redictors are mixed. Ba yes-mixtures can also b e u sed for un iv er- sal prediction (Hutter, 2003). F or the control case, the idea of using mixtur es of exp ert-con trollers has b een previously ev oke d in mo d els like the MOSAIC-arc hitecture (Haruno et al., 2001). Univ ersal learning with Ba y es m ixtures of exp erts in reactiv e en vironments has b een studied in (P oland an d Hutter, 2005; Hutter, 2002). • Sto chastic action sele ction. Other s to c hastic action selection approac hes are fou n d in Wyatt (1997) w ho examines exploration s trategies f or (PO)MDPs, in learnin g au- tomata (Narendr a and Th athac h ar , 1974) and in probabilit y matc h in g (R.O. Duda, 2001) amongst others. In p articular, Wya tt (1997) discusses theoretical prop erties of an extension to pr ob ability matching in the conte xt of multi-a rmed bandit problems. There, it is prop osed to c h o ose a lev er according to ho w lik ely it is to b e optimal and it is sho w n that this strateg y con v erges, th us pr o v id ing a simple metho d for guid ing exploration. • R elative entr opy criterion. The u sage of a minimum relativ e entrop y criterion to deriv e cont rol la ws un derlies the KL-control metho ds dev elop ed in T o doro v (2006, 2009); Kapp en et al. (200 9 ). Th ere, it has b een shown that a large class of optimal con trol problems can b e solv ed v ery efficien tly if the problem statemen t is reformulate d as the minimization of the deviation of the dyn amics of a controlle d s y s tem f rom the uncon trolled s ystem. A related idea is to conceptualize p lanning as an inf er en ce problem (T ous s ain t et al., 2006). This approac h is based on an equiv alence b et we en maximization of the exp ected fu ture return and lik eliho od maximizati on whic h is b oth applicable to MDPs and POMDPs. Algorithms based on this dualit y ha ve b ecome an activ e field of curr en t research. See for example Rasmussen and Deisenroth (2008), where v ery fast mo del-based RL tec hn iques are used for con trol in contin uous state and action spaces. 7. Conclusions This work in tro du ces the Ba ye sian con trol rule, a Ba y esian rule for adap tive con trol. The k ey feature of this rule is the s p ecial treatment of actions based on causal calculus and the decomp osition of an adaptiv e agent in to a mixture of operation mo d es, i.e. environmen t- sp ecific agen ts. Th e rule is d eriv ed b y minimizing the exp ected relativ e en trop y from the true operation mo d e and b y carefully distinguishing b et w een actio ns and observ ations. F ur - thermore, the Bay esian con trol rule tu rns out to b e exactly the pr ed ictiv e d istribution o ver the next action giv en the past inte ractions that one w ould ob tain by using only probab ility and causal calculus. F urth ermore, it is sho wn th at agen ts constructed with the Ba y esian 27 Or tega and Braun con trol rule con v erge to the true op eration mo de und er mild assumptions: b oun d edness, whic h related to ergo dicit y; and consistency , d emanding that tw o indistinguish ab le h yp othe- ses share the same p olicy . W e ha ve presented the Bay esian con trol rule as a w a y to solv e adaptiv e con trol problems based on a minimum relativ e entrop y pr inciple. Th us, the Ba y esian cont rol ru le can either b e r egarded as a new p rincipled app roac h to adaptiv e con trol und er a no v el optimalit y criterion or as a heuristic appr o ximation to traditional Ba ye s-optimal con trol. Since it tak es on a similar form to Ba y es’ r ule, the adaptive control problem could then b e translated in to an on-line inference p roblem where actions are sampled sto chastic ally f rom a p osterior distribution. It is imp ortant to n ote, how ev er, that the problem statemen t as formulat ed here and th e usual Ba ye s-optimal app r oac h in adaptive con trol are not the same. In the future the r elationship b et w een these t w o problem statemen ts deserv es further inv estigation. 28 A Minimum Rela tive Entropy Principle for Learning and Acting Ac kno wledgmen t s W e thank David Wingate, Zoub in Ghahramani, J os ´ e Aliste, Jos ´ e Donoso, Humb erto Mat- urana and the anon ymous review ers for commen ts on earlier versions of this man uscript and/or inspiring discussions. W e thank the Ministerio de Planificaci´ on de Chile (MIDE- PLAN) and the B¨ ohr inger-Ingelheim-F onds (BIF) for fund ing. App endix A. Pro ofs A.1 Pro of of Theorem 1 Pro of T he pro of follo ws th e s ame line of argument as the solution to Equation 3 with the crucial difference that actions are treated as interv entio ns. Consid er without loss of generalit y the su mmand P m P ( m ) C a t m in Equation 9. Note that th e relativ e en tropy can b e written as a difference of t wo logarithms, w here only one term dep end s on P r to b e v aried. Therefore, one can integrat e out the other term and write it as a constan t c . This yields c − X m P ( m ) X ao 0, there is a C ( m ) ≥ 0, suc h th at for all m ′ ∈ M , all t ∈ N t and all T ⊂ N t , the inequalit y g m ( m ′ ; T m ′ ) − G m ( m ′ ; T m ′ ) ≤ C ( m ) holds with probabilit y ≥ 1 − δ ′ . How eve r, due to (15), G m ( m ′ ; T m ′ ) ≥ 0 for all m ′ ∈ M . Thus, g m ( m ′ ; T m ′ ) ≥ − C ( m ) . If all the previous in equalities hold sim ultaneously then the dive rgence pro cess can b e b ound ed as wel l. That is, the inequalit y d t ( m ∗ k m ) ≥ − M C ( m ) (20) holds with probabilit y ≥ (1 − δ ′ ) M where M : = |M| . Ch o ose β ( m ) : = max { 0 , ln P ( m ) P ( m ∗ ) } . 30 A Minimum Rela tive Entropy Principle for Learning and Acting Since 0 ≥ ln P ( m ) P ( m ∗ ) − β ( m ), it can b e added to the righ t hand side of (20). Using the definition of d t ( m ∗ k m ), taking the exp onen tial and r earranging the terms one obtains P ( m ∗ ) t Y τ =1 P ( o τ | m ∗ , ao <τ a τ ) ≥ e − α ( m ) P ( m ) t Y τ =1 P ( o τ | m ∗ , ao <τ a τ ) where α ( m ) : = M C ( m ) + β ( m ) ≥ 0. Identi fying the p osterior probab ilities of m ∗ and m b y d ivid ing b oth sides by the norm alizing constan t yields the inequalit y P ( m ∗ | ˆ ao ≤ t ) ≥ e − α ( m ) P ( m | ˆ ao ≤ t ) . This inequalit y holds simulta neously for all m ∈ M with probabilit y ≥ (1 − δ ′ ) M 2 and in particular for λ : = min m { e − α ( m ) } , that is, P ( m ∗ | ˆ ao ≤ t ) ≥ λP ( m | ˆ ao ≤ t ) . But sin ce th is is v alid for any m ∈ M , and b ecause max m { P ( m | ˆ ao ≤ t ) } ≥ 1 M , one gets P ( m ∗ | ˆ ao ≤ t ) ≥ λ M , with pr ob ab ility ≥ 1 − δ f or arb itrary δ > 0 related to δ ′ through the equation δ ′ : = 1 − M 2 √ 1 − δ . A.3 Pro of of Theorem 3 Pro of The div ergence pro cess d t ( m ∗ k m ) can b e decomp osed in to a sum of sub -d iv ergences (see Equation 14) d t ( m ∗ k m ) = X m ′ g ( m ′ ; T m ′ ) . (21) F urthermore, for eve ry m ′ ∈ M , one has that for all δ > 0, th ere is a C ≥ 0, such that for all t ∈ N and for all T ⊂ N t g ( m ′ ; T ) − G ( m ′ ; T ) ≤ C ( m ) with p robabilit y ≥ 1 − δ ′ . Applying this b ound to the su mmands in (21) yields the lo wer b ound X m ′ g ( m ′ ; T m ′ ) ≥ X m ′ G ( m ′ ; T m ′ ) − C ( m ) whic h h olds with pr ob ab ility ≥ (1 − δ ′ ) M , wh ere M : = |M| . Due to Inequalit y 15, one has that for all m ′ 6 = m ∗ , G ( m ′ ; T m ′ ) ≥ 0. Hence, X m ′ G ( m ′ ; T m ′ ) − C ( m ) ≥ G ( m ∗ ; T m ∗ ) − M C where C : = max m { C ( m ) } . The mem b ers of the set T m ∗ are determined s to chastica lly; more sp ecifically , the i th mem b er is in cluded into T m ∗ with pr obabilit y P ( m ∗ | ˆ ao ≤ i ). But since 31 Or tega and Braun m / ∈ [ m ∗ ], one has that G ( m ∗ ; T m ∗ ) → ∞ as t → ∞ with p r obabilit y ≥ 1 − δ ′ for arb itrarily c hosen δ ′ > 0. Th is implies that lim t →∞ d t ( m ∗ k m ) ≥ lim t →∞ G ( m ∗ ; T m ∗ ) − M C ր ∞ with probabilit y ≥ 1 − δ , where δ > 0 is arbitrary and r elated to δ ′ as δ = 1 − (1 − δ ′ ) M +1 . Using this result in the u pp er b oun d for p osterior probabilities yields the fi nal result 0 ≤ lim t →∞ P ( m | ˆ ao ≤ t ) ≤ lim t →∞ P ( m ) P ( m ∗ ) e − d t ( m ∗ k m ) = 0 . A.4 Pro of of Theorem 4 Pro of W e will u se the abbreviations p m ( t ) : = P ( a t | m, ˆ ao 0 and δ ′ > 0, let t 0 ( m ) b e the time su c h that for all t ≥ t 0 ( m ), w m ( t ) < ε ′ . C h o osing t 0 : = max m { t 0 ( m ) } , the previous inequalit y holds for all m and t ≥ t 0 sim ultaneously with probabilit y ≥ (1 − δ ′ ) M . Hence, X m / ∈ [ m ∗ ] p m ( t ) w m ( t ) ≤ X m / ∈ [ m ∗ ] w m ( t ) < M ε ′ . (23) T o b ound the second sum in (22) one p ro ceeds as follo w s . F or eve ry m em b er m ∈ [ m ∗ ], one has that p m ( t ) → p m ∗ ( t ) as t → ∞ . Hence, follo win g a s im ilar construction as ab o v e, one can choose t ′ 0 suc h th at for all t ≥ t ′ 0 and m ∈ [ m ∗ ], the in equalities p m ( t ) − p m ∗ ( t ) < ε ′ hold simultaneously for the precision ε ′ > 0. Applying this to the first sum yields the b ound s X m ∈ [ m ∗ ] p m ∗ ( t ) − ε ′ w m ( t ) ≤ X m ∈ [ m ∗ ] p m ( t ) w m ( t ) ≤ X m ∈ [ m ∗ ] p m ∗ ( t ) + ε ′ w m ( t ) . 32 A Minimum Rela tive Entropy Principle for Learning and Acting Here p m ∗ ( t ) ± ε ′ are m ultiplicativ e constan ts that can b e placed in fron t of the sum . Note that 1 ≥ X m ∈ [ m ∗ ] w m ( t ) = 1 − X m / ∈ [ m ∗ ] w m ( t ) > 1 − ε. Use of th e ab o ve in equalities allo ws simp lifying the lo w er and up p er b oun ds resp ectiv ely: p m ∗ ( t ) − ε ′ X m ∈ [ m ∗ ] w m ( t ) > p m ∗ ( t )(1 − ε ′ ) − ε ′ ≥ p m ∗ ( t ) − 2 ε ′ , p m ∗ ( t ) + ε ′ X m ∈ [ m ∗ ] w m ( t ) ≤ p m ∗ ( t ) + ε ′ < p m ∗ ( t ) + 2 ε ′ . (24) Com bining th e inequalities (23) and (24) in (22) yields the fi nal result: P ( a t | ˆ ao 0 related to δ ′ as δ ′ = 1 − M √ 1 − δ and arbitrary precision ε . A.5 Gibbs Sampling Implemen tation for MDP agent Inserting the lik eliho o d giv en in E quation (17) into Equation (13) of the Ba y esian con tr ol rule, one obtains th e follo win g expression for the p osterior P ( m | ˆ a ≤ t , o ≤ t ) = P ( x ′ | m, x, a ) P ( r | m, x, a, x ′ ) P ( m | ˆ a
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment