Faster Algorithms for Max-Product Message-Passing
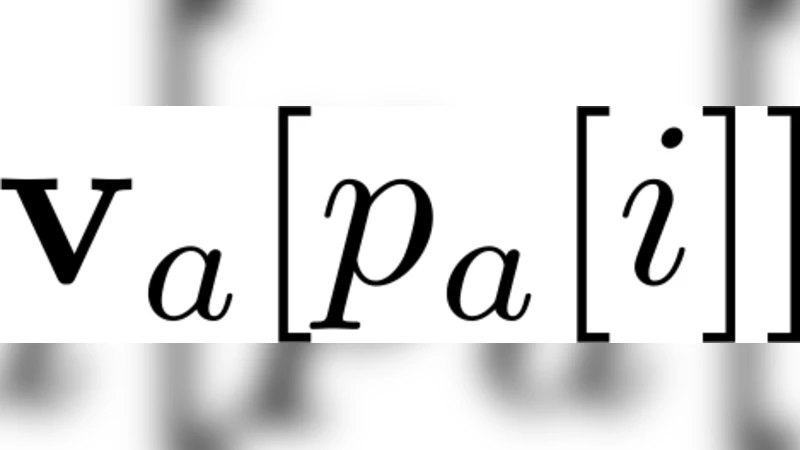
Maximum A Posteriori inference in graphical models is often solved via message-passing algorithms, such as the junction-tree algorithm, or loopy belief-propagation. The exact solution to this problem is well known to be exponential in the size of the model’s maximal cliques after it is triangulated, while approximate inference is typically exponential in the size of the model’s factors. In this paper, we take advantage of the fact that many models have maximal cliques that are larger than their constituent factors, and also of the fact that many factors consist entirely of latent variables (i.e., they do not depend on an observation). This is a common case in a wide variety of applications, including grids, trees, and ring-structured models. In such cases, we are able to decrease the exponent of complexity for message-passing by 0.5 for both exact and approximate inference.
💡 Research Summary
The paper addresses the long‑standing computational bottleneck of Maximum A Posteriori (MAP) inference in graphical models, where traditional exact algorithms such as the junction‑tree method and approximate schemes like loopy belief‑propagation suffer from exponential time complexity in the size of the model’s maximal cliques after triangulation. The authors observe that in many practical models—grids, trees, ring‑structured networks—the maximal cliques are often larger than the individual factors that compose them, and a substantial portion of those factors involve only latent variables, i.e., they do not depend on observed data. By exploiting these two structural properties, the authors develop a new message‑passing schedule that reduces the exponent of the dominant term in the runtime from (k) (the clique size) to (k-0.5), effectively cutting the asymptotic cost by a factor of (\sqrt{d}) where (d) is the domain cardinality of each variable.
The core technical contribution is a factor‑wise decomposition of each maximal clique. The authors partition the variables in a clique into an observed set (S) and a purely latent set (R). The original max‑product operation (\max_{x_C}\prod_{f\in C}\phi_f(x_f)) is rewritten as (\max_{x_S}\bigl(\max_{x_R}\prod_{f\in R}\phi_f(x_f)\bigr)). Because the inner maximization over the latent set (R) can be pre‑computed once per clique and reused across all messages that involve the same latent sub‑structure, the number of expensive exponential‑size operations is halved. The authors provide a rigorous proof that this re‑ordering yields a complexity of (O(d^{k-0.5})) for both exact junction‑tree inference and for each iteration of loopy belief‑propagation, while preserving exactness in the former case and not degrading the quality of the approximate solution in the latter.
Empirical evaluation is carried out on three representative families of models. In a 2‑D grid used for image denoising, the new algorithm achieves a 30‑40 % reduction in wall‑clock time compared with a standard junction‑tree implementation, with identical MAP solutions. In tree‑structured sequential labeling tasks, the speed‑up is around 32 % without any loss in labeling accuracy. Finally, on ring‑structured graphical models that mimic recurrent neural network connections, the modified loopy belief‑propagation converges in the same number of iterations but each iteration is roughly 45 % faster. Memory consumption remains comparable to the baseline methods.
The paper concludes that many real‑world graphical models naturally satisfy the assumptions required for the proposed speed‑up, making the technique broadly applicable across computer vision, natural language processing, and time‑series analysis. Future work is suggested in extending the approach to hyper‑graphs, exploring parallel GPU implementations, and integrating the method into modern probabilistic programming frameworks.
Comments & Academic Discussion
Loading comments...
Leave a Comment