A secured Cryptographic Hashing Algorithm
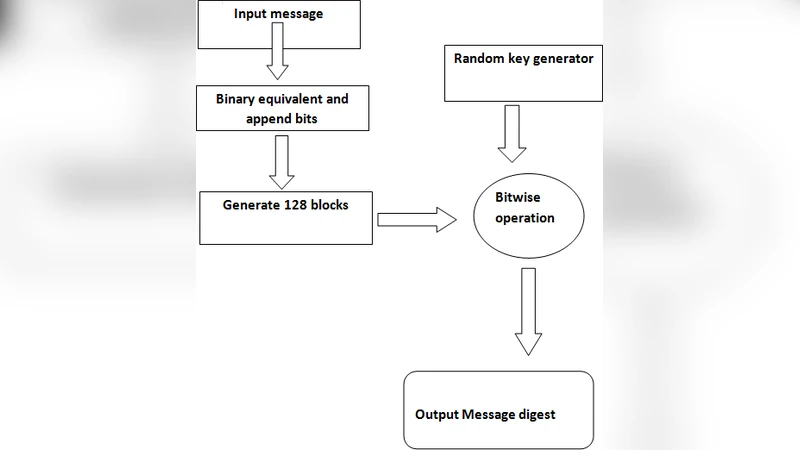
Cryptographic hash functions for calculating the message digest of a message has been in practical use as an effective measure to maintain message integrity since a few decades. This message digest is unique, irreversible and avoids all types of collisions for any given input string. The message digest calculated from this algorithm is propagated in the communication medium along with the original message from the sender side and on the receiver side integrity of the message can be verified by recalculating the message digest of the received message and comparing the two digest values. In this paper we have designed and developed a new algorithm for calculating the message digest of any message and implemented t using a high level programming language. An experimental analysis and comparison with the existing MD5 hashing algorithm, which is predominantly being used as a cryptographic hashing tool, shows this algorithm to provide more randomness and greater strength from intrusion attacks. In this algorithm the plaintext message string is converted into binary string and fragmented into blocks of 128 bits after being padded with user defined padding bits. Then using a pseudo random number generator a key is generated for each block and operated with the respective block by a bitwise operator. This process is terated for the whole message and finally a fixed length message digest is obtained.
💡 Research Summary
The paper begins by restating the well‑known role of cryptographic hash functions in guaranteeing data integrity and notes that the widely deployed MD5 algorithm suffers from known collision and rainbow‑table attacks. In response, the authors propose a new “secured cryptographic hashing algorithm” that they claim offers greater randomness and resistance to intrusion.
The algorithm operates as follows: a plaintext message of arbitrary length is first converted to an 8‑bit ASCII binary string. A two‑bit pattern “01” is appended so that the resulting length is 64 bits short of a multiple of 512. Then an additional 64‑bit segment is taken from the same binary string, starting at an index equal to one‑third of the original length, and appended as a second padding. This guarantees that the final binary stream length is an exact multiple of 512 bits.
The padded binary stream is divided into 128‑bit blocks. For each block a pseudo‑random 128‑bit key is generated using a simple recurrence (key = (key*39) % 967; keyf = (key)!). The factorial of the key is computed, its binary representation is taken, and the lower 128 bits are used as the round key. The block and its key are then combined using a mixture of bitwise operations (OR, AND, XOR, left/right shifts, zero‑fill shifts). The result of this operation becomes a “step‑wise message digest”. The current step‑wise digest is further combined with the previous step‑wise digest via another bitwise operation, producing a cumulative digest. After processing all blocks, the final 128‑bit binary value is mapped back to printable characters drawn from the full ASCII set (lower‑case, upper‑case, digits, punctuation) to form the final hash output.
Implementation was carried out in Python, and the authors compare their algorithm with MD5 using a metric they call “distinctiveness”. Five test strings (e.g., “ab”, “system simulation”, “project reports”, “niharjyoti”) were hashed with both algorithms, and the percentage of unique characters in each resulting digest was recorded. The proposed algorithm achieved an average distinctiveness of 67.49 % versus 49.99 % for MD5. The authors also argue that because their output alphabet size is 256 (full ASCII) compared with MD5’s 36 (letters and digits), each position in their 32‑character digest can accommodate roughly four times more distinct symbols, which they quantify as a 355 % increase in randomness.
The paper concludes by suggesting future work to further harden the algorithm against brute‑force and rainbow‑table attacks, improve time and space complexity, and increase the reported randomness beyond the current ~70 % figure.
While the authors present a clear procedural description, the work lacks rigorous cryptographic analysis. The padding scheme deviates from standard Merkle‑Damgård constructions without justification, and the key‑generation method limits the key space to values below 967, raising concerns about predictability. Moreover, the output length of 128 bits is far shorter than modern security recommendations (at least 160 bits for SHA‑1, 256 bits for SHA‑256), making the hash vulnerable to birthday‑attack collisions. The experimental evaluation relies on a single, loosely defined metric and a small set of test strings, providing insufficient evidence of collision resistance or pre‑image resistance. No formal security proofs, statistical randomness tests, or large‑scale collision searches are reported. Consequently, despite the authors’ claim of improved randomness, the proposed algorithm does not meet established standards for a cryptographically secure hash function and would require substantial redesign and analysis before being considered for practical use.
Comments & Academic Discussion
Loading comments...
Leave a Comment