Automatically detecting discourse segments is an important preliminary step towards full discourse parsing. Previous research on discourse segmentation have relied on the assumption that elementary discourse units (EDUs) in a document always form a linear sequence (i.e., they can never be nested). Unfortunately, this assumption turns out to be too strong, for some theories of discourse like SDRT allows for nested discourse units. In this paper, we present a simple approach to discourse segmentation that is able to produce nested EDUs. Our approach builds on standard multi-class classification techniques combined with a simple repairing heuristic that enforces global coherence. Our system was developed and evaluated on the first round of annotations provided by the French Annodis project (an ongoing effort to create a discourse bank for French). Cross-validated on only 47 documents (1,445 EDUs), our system achieves encouraging performance results with an F-score of 73% for finding EDUs.
Deep Dive into Learning Recursive Segments for Discourse Parsing.
Automatically detecting discourse segments is an important preliminary step towards full discourse parsing. Previous research on discourse segmentation have relied on the assumption that elementary discourse units (EDUs) in a document always form a linear sequence (i.e., they can never be nested). Unfortunately, this assumption turns out to be too strong, for some theories of discourse like SDRT allows for nested discourse units. In this paper, we present a simple approach to discourse segmentation that is able to produce nested EDUs. Our approach builds on standard multi-class classification techniques combined with a simple repairing heuristic that enforces global coherence. Our system was developed and evaluated on the first round of annotations provided by the French Annodis project (an ongoing effort to create a discourse bank for French). Cross-validated on only 47 documents (1,445 EDUs), our system achieves encouraging performance results with an F-score of 73% for finding EDUs.
arXiv:1003.5372v1 [cs.CL] 28 Mar 2010
Learning Recursive Segments for Discourse Parsing
Stergos Afantenos∗, Pascal Denis†, Philippe Muller∗†, Laurence Danlos†
∗Institut de recherche en informatique de Toulouse (IRIT)
Université Paul Sabatier
118 route de Narbonne, 31062 Toulouse Cedex 9, France
{stergos.afantenos, philippe.muller}@irit.fr
†Equipe-Projet Alpage
INRIA & Université Paris 7
30 rue Château des Rentiers, 75013 Paris, France
laurence.danlos@linguist.jussieu.fr, pascal.denis@inria.fr
Abstract
Automatically detecting discourse segments is an important preliminary step towards full discourse parsing. Pre-
vious research on discourse segmentation have relied on the assumption that elementary discourse units (EDUs)
in a document always form a linear sequence (i.e., they can never be nested). Unfortunately, this assumption
turns out to be too strong, for some theories of discourse like SDRT allows for nested discourse units. In this
paper, we present a simple approach to discourse segmentation that is able to produce nested EDUs. Our ap-
proach builds on standard multi-class classification techniques combined with a simple repairing heuristic that
enforces global coherence. Our system was developed and evaluated on the first round of annotations provided
by the French Annodis project (an ongoing effort to create a discourse bank for French). Cross-validated on only
47 documents (1, 445 EDUs), our system achieves encouraging performance results with an F-score of 73% for
finding EDUs.
1.
Introduction
Discourse parsing is the analysis of a text from
a global, structural perspective: how parts of a
discourse contribute to its global interpretation,
accounting for semantic and pragmatic effects
beyond simple sentence concatenation. This task
consists in two main steps: (i) finding the elemen-
tary discourse units (henceforth EDUs), and (ii)
organizing them in a way that make explicit their
functional (aka rhetorical) relations.
Popular
theories of discourse include Rhetorical Struc-
ture Theory (RST) (Mann and Thompson, 1987),
Discourse Lexicalized Tree-Adjoining Grammar
(DLTAG) (Webber, 2004), Segmented Discourse
Representation Theory (SDRT) (Asher, 1993).
Each of these theoretical frameworks has been at
the center of important corpus building efforts,
see
(Carlson et al., 2003;
Prasad et al., 2004;
Baldridge et al., 2007)
respectively.
In
the
present work, we focus on the first step, namely
segmenting a discourse into EDUs, within a
larger project aiming at building an SDRT
discourse corpus of French texts.
In addition to being a necessary step in discourse
parsing, discourse segmentation, could also be
useful as a stand-alone application for a variety
of other tasks where EDUs could provide sim-
pler input than sentences. Examples of such tasks
are: automatic summarization and sentence com-
pression, bitext alignment, translation, chunk-
ing/syntactic parsing.
The first discourse segmentation system dates
back to the rule-based work of (Ejerhed, 1996),
which was a component in the RST-based
parser
of
(Marcu, 2000).
More
recently,
(Tofiloski et al., 2009)
tested
a
rule-based
segmenter
on
top
of
a
syntactic
parser,
achieving
F-score
of
80-85%
in
segment
boundary identification on a slightly modi-
fied RST corpus.
Machine learning based
segmentation
systems
have
also
been
pro-
posed, notably by (Soricut and Marcu, 2003),
(Sporleder and Lapata, 2005)
and
(Fisher and Roark, 2007).
The latter report
F-score of 90.5% in boundary detection (and
85.3% in correct bracketing) on the RST corpus.
Discourse segmentation is to large extent theory
dependent, for different theories make different
assumptions on what EDUs can be. Carried out
on the RST corpus, previous work on discourse
segmentation has exploited an important particu-
larity of this corpus: namely, the fact that it does
not have any embedded EDUs. These approaches
have been able to recast discourse segmentation
as a binary classification problem: that is, each
text position (token or token separator) is either a
segment boundary or not. By contrast to RST,
other theories like SDRT allows for embedded
EDUs: embedding is used to encode modifying
clauses like non restrictive relatives (including re-
duced relatives) and appositions. As will be dis-
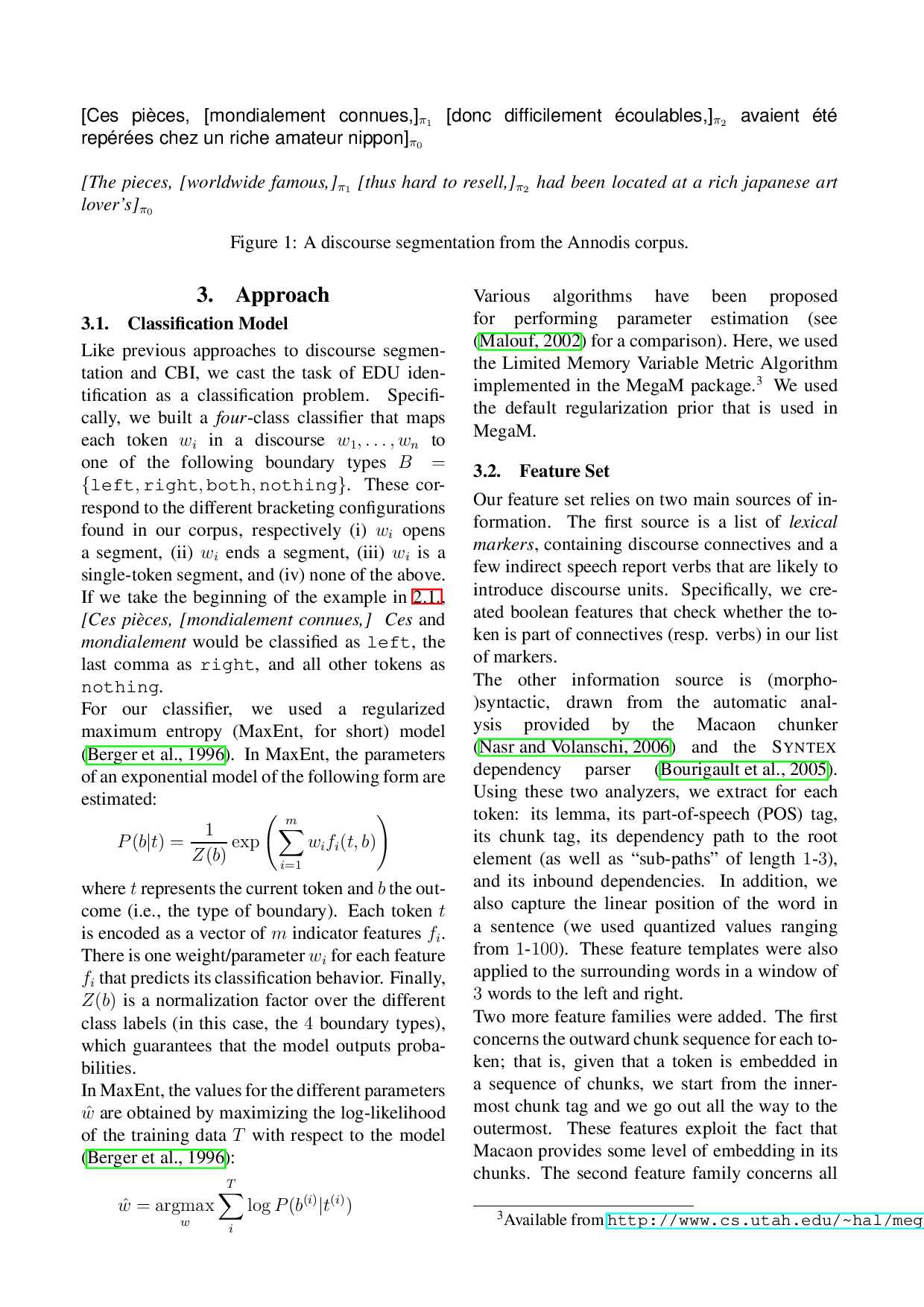
cussed in Section 2., our SDRT-based corpus does
contain close to 10% of nested EDUs.
Predicting nested structures introduces additional
difficulties, in particular that of outputting a co-
herent, balanced bracketing.
This characteris-
tic renders discourse segmentation akin to syn-
tactic clause boundary identification (CBI), a
task which has received some attention from
the CL community.
The main approach to
CBI is to classify tokens into three classes for
clause start, end, or inside. The best results ob-
tained during the CoNLL-2001 campaign were
89-90% for boundary detection and 81.73% for
correct clause identification (correct guessing
of start and end), with boosted decision trees
(Carreras and Màrquez, 2001).
We hav
…(Full text truncated)…
This content is AI-processed based on ArXiv data.