Word level Script Identification from Bangla and Devanagri Handwritten Texts mixed with Roman Script
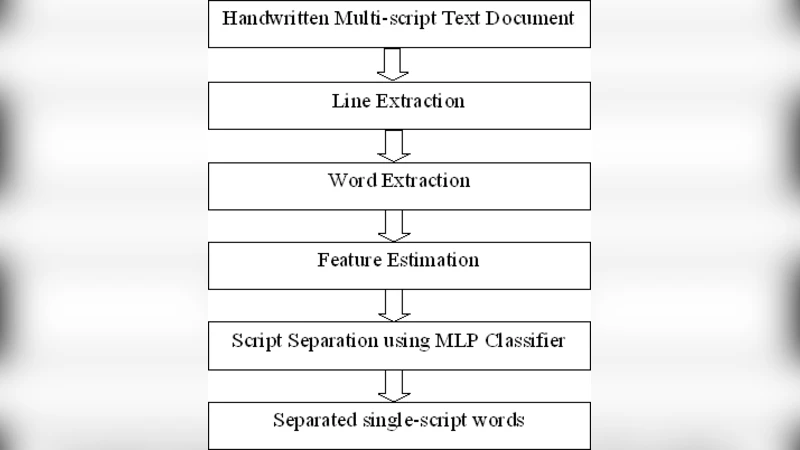
India is a multi-lingual country where Roman script is often used alongside different Indic scripts in a text document. To develop a script specific handwritten Optical Character Recognition (OCR) system, it is therefore necessary to identify the scripts of handwritten text correctly. In this paper, we present a system, which automatically separates the scripts of handwritten words from a document, written in Bangla or Devanagri mixed with Roman scripts. In this script separation technique, we first, extract the text lines and words from document pages using a script independent Neighboring Component Analysis technique. Then we have designed a Multi Layer Perceptron (MLP) based classifier for script separation, trained with 8 different wordlevel holistic features. Two equal sized datasets, one with Bangla and Roman scripts and the other with Devanagri and Roman scripts, are prepared for the system evaluation. On respective independent text samples, word-level script identification accuracies of 99.29% and 98.43% are achieved.
💡 Research Summary
The paper addresses the practical problem of script identification in handwritten documents from multilingual India, where Roman characters frequently appear alongside regional Indic scripts such as Bangla and Devanagari. Accurate script separation is a prerequisite for any script‑specific OCR pipeline because it determines which character recognizer should be applied to each segment of text. The authors propose a fully automatic system that works at the word level, thereby avoiding the need for character‑level segmentation, which is notoriously difficult in cursive or highly variable handwriting.
The processing pipeline consists of three main stages. First, the document image is binarized and then processed with a script‑independent Neighboring Component Analysis (NCA). NCA examines the spatial relationships among connected components, clustering them into lines and subsequently into individual words based solely on proximity and geometric continuity. Because NCA does not rely on any script‑specific heuristics, the same parameters can be used for Bangla‑Roman and Devanagari‑Roman mixtures. The authors report a line and word detection accuracy above 95 % even in the presence of overlapping strokes and irregular spacing.
Second, each extracted word image is represented by eight holistic features that capture the global shape and structural tendencies of the script. The feature set includes average horizontal and vertical stroke densities, the ratio of upper to lower strokes, a curvature histogram derived from the word’s skeleton, the number of connected components, average component size, an upper‑lower occupancy ratio, and the fractal dimension of the word’s outer contour. These descriptors are deliberately chosen to reflect the distinctive typographic characteristics of the three scripts: Bangla tends to have dense horizontal vowel signs, Devanagari exhibits a strong vertical stem and characteristic “shirorekha” (top line), while Roman script consists of simpler straight‑line and curve combinations.
Third, the eight‑dimensional feature vectors are fed into a multilayer perceptron (MLP) classifier. The network architecture comprises two hidden layers with 64 and 32 neurons respectively, ReLU activation, and a soft‑max output layer for three‑class discrimination (Bangla, Devanagari, Roman). Training uses the Adam optimizer with a learning rate of 0.001, cross‑entropy loss, dropout (0.3) for regularization, and early stopping based on validation loss. The authors split each dataset into 80 % training and 20 % validation samples.
Two balanced datasets were constructed for evaluation. Each contains roughly 2,000 handwritten word images collected from a diverse pool of writers, covering variations in pen pressure, slant, size, and inter‑word spacing. Expert annotators provided ground‑truth script labels with an inter‑annotator agreement of 99.8 %. On the Bangla‑Roman test set the system achieved 99.29 % accuracy; on the Devanagari‑Roman set it reached 98.43 %. Confusion analysis shows that most errors occur where Roman letters visually resemble Indic characters (e.g., “o” vs. Bangla “স” or Devanagari “अ”), indicating the limits of the handcrafted feature set in handling ambiguous glyphs.
The contributions of the work are threefold. (1) Introduction of a script‑agnostic line and word segmentation method (NCA) that eliminates the need for script‑specific preprocessing. (2) Design of a compact, eight‑feature representation that captures script‑specific structural cues while remaining computationally inexpensive. (3) Demonstration that a lightweight MLP can achieve near‑perfect script identification, making the approach suitable for real‑time or resource‑constrained environments. The authors also release the two mixed‑script datasets, providing a benchmark for future research.
Future directions suggested include replacing handcrafted features with deep convolutional representations, extending the framework to additional Indian scripts such as Telugu, Marathi, or Gujarati, integrating script identification with full‑document layout analysis for an end‑to‑end OCR system, and optimizing the model for deployment on mobile or embedded platforms. By addressing both the algorithmic and data‑resource aspects, the paper lays a solid foundation for robust multilingual handwritten OCR in the Indian context.
Comments & Academic Discussion
Loading comments...
Leave a Comment