A Security Based Data Mining Approach in Data Grid
Grid computing is the next logical step to distributed computing. Main objective of grid computing is an innovative approach to share resources such as CPU usage; memory sharing and software sharing. Data Grids provide transparent access to semantically related data resources in a heterogeneous system. The system incorporates both data mining and grid computing techniques where Grid application reduces the time for sending results to several clients at the same time and Data mining application on computational grids gives fast and sophisticated results to users. In this work, grid based data mining technique is used to do automatic allocation based on probabilistic mining frequent sequence algorithm. It finds frequent sequences for many users at a time with accurate result. It also includes the trust management architecture for trust enhanced security.
💡 Research Summary
The paper presents a framework that integrates data mining and grid computing to enable efficient analysis of large, heterogeneous datasets distributed across a data grid. The authors begin by outlining the motivations for grid computing—sharing CPU, memory, and software resources across a network to form a virtual supercomputer—and for data grids, which provide transparent access to semantically related data sources managed by different systems. They argue that combining these two paradigms can reduce the latency of delivering mining results to multiple clients and can accelerate the mining process itself.
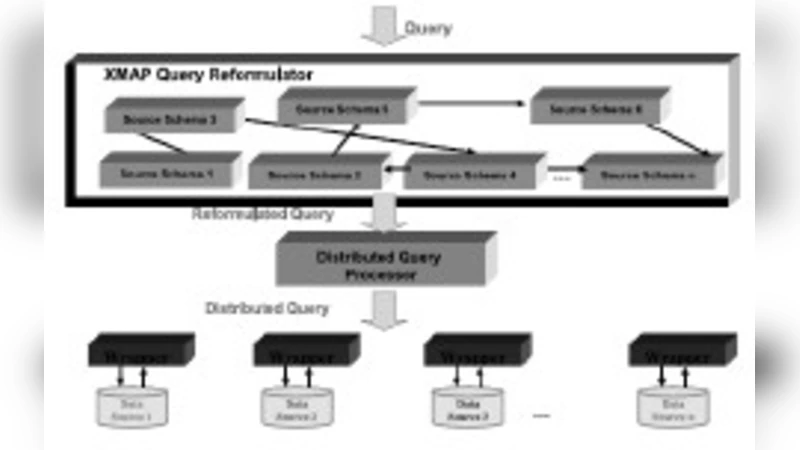
The core contribution is a three‑layer architecture that couples a probabilistic frequent‑sequence mining algorithm with grid‑based query processing and a trust‑enhanced security model. At the top layer, the XMAP framework acts as a query reformulation engine. When a user submits a high‑level query, XMAP translates it into one or more concrete sub‑queries that respect the schemas of the underlying data sources. This semantic mediation is intended to hide heterogeneity and allow a single query to retrieve data from multiple repositories.
The middle layer employs OGSA‑DQP (Open Grid Services Architecture – Distributed Query Processing) to execute the reformulated queries in parallel. The system’s scheduler monitors the CPU utilization and memory load of each “gridlet” (a computational node) and assigns sub‑queries to the least‑loaded nodes. Sub‑queries are wrapped by OGSA‑DAI services, which provide a uniform data‑access interface to relational databases, XML stores, or file systems. After execution, results from all sub‑queries are aggregated by a result‑aggregation module and returned to the client.
For the mining component, the authors adopt a “Probabilistic Mining Frequent Sequences” algorithm, described only in high‑level terms. They claim that the probabilistic model improves scalability over classic Apriori‑based sequence mining, especially when dealing with massive logs. The SPRINT algorithm is mentioned as the underlying search mechanism, but the paper lacks a formal definition, complexity analysis, or comparative benchmarks.
Security is addressed through a trust management architecture. Each participant (client or gridlet) receives a trust score based on past behavior; authentication and authorization decisions are made according to these scores. The system also applies integrity checks and encryption to protect data in transit, aiming to mitigate the risks inherent in a distributed environment. However, the paper does not detail how trust scores are calculated, updated, or how the system reacts to compromised nodes.
The related‑work section surveys several grid‑based integration projects, such as Hyper (a peer‑to‑peer schema‑mapping framework), GDMS (a wrapper/mediator approach for heterogeneous sources), and earlier OGSA‑DQP implementations. The authors position their work as novel because it simultaneously tackles probabilistic mining and trust‑based security, yet the lack of experimental evaluation makes it difficult to assess the real impact.
In the conclusion, the authors reiterate that grid‑enabled data mining can bring analytics closer to where data resides, reducing the need for costly data movement. They suggest future directions including automated schema mapping, dynamic trust adaptation, and real‑time performance tuning. Overall, the paper proposes an interesting integration of existing grid services with a probabilistic mining algorithm and a trust model, but it falls short on implementation details, quantitative performance results, and rigorous security analysis, limiting its contribution to a conceptual design rather than a validated solution.
Comments & Academic Discussion
Loading comments...
Leave a Comment