Feature Hashing for Large Scale Multitask Learning
Empirical evidence suggests that hashing is an effective strategy for dimensionality reduction and practical nonparametric estimation. In this paper we provide exponential tail bounds for feature hashing and show that the interaction between random subspaces is negligible with high probability. We demonstrate the feasibility of this approach with experimental results for a new use case – multitask learning with hundreds of thousands of tasks.
💡 Research Summary
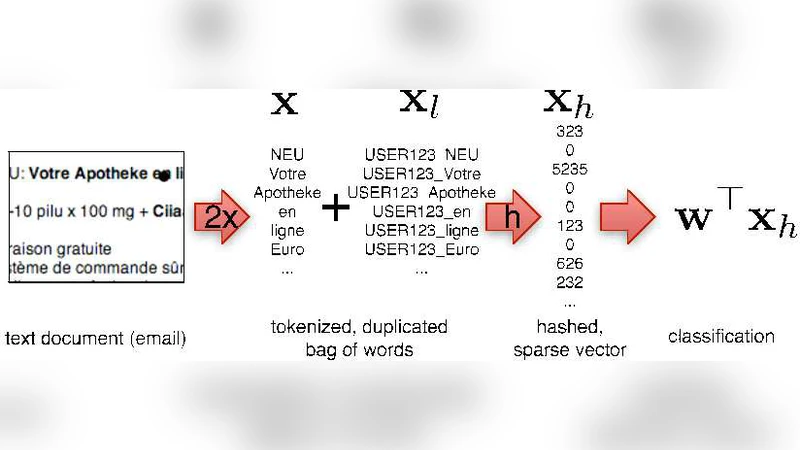
The paper investigates the use of feature hashing—also known as the “hashing trick”—as a principled dimensionality‑reduction technique for extremely large‑scale multitask learning. The authors first formalize the hashing process: an input vector x∈ℝ^d is mapped to a k‑dimensional compressed vector φ(x) by two independent random functions, an index hash h:{1,…,d}→{1,…,k} and a sign hash ξ:{1,…,d}→{−1,+1}. Each component of φ(x) is the signed sum of all original features that collide on the same hash bucket. This construction yields an unbiased estimator of the original inner product, i.e., E
Comments & Academic Discussion
Loading comments...
Leave a Comment