A Trustability Metric for Code Search based on Developer Karma
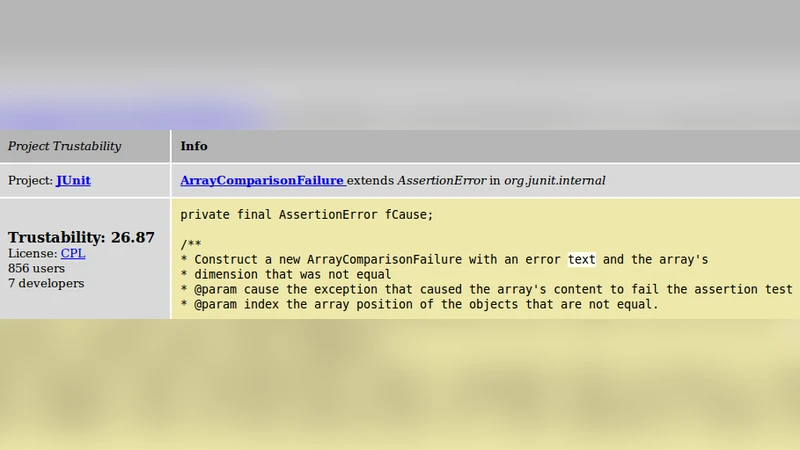
The promise of search-driven development is that developers will save time and resources by reusing external code in their local projects. To efficiently integrate this code, users must be able to trust it, thus trustability of code search results is just as important as their relevance. In this paper, we introduce a trustability metric to help users assess the quality of code search results and therefore ease the cost-benefit analysis they undertake trying to find suitable integration candidates. The proposed trustability metric incorporates both user votes and cross-project activity of developers to calculate a “karma” value for each developer. Through the karma value of all its developers a project is ranked on a trustability scale. We present JBender, a proof-of-concept code search engine which implements our trustability metric and we discuss preliminary results from an evaluation of the prototype.
💡 Research Summary
The paper addresses a critical gap in modern code‑search tools: while most systems rank results by textual relevance, developers also need to assess how trustworthy a candidate snippet or library is before integrating it into their own projects. To this end, the authors propose a “trustability” metric that quantifies the reputation of the developers behind a project and aggregates these reputations into a project‑level score. The metric combines two orthogonal sources of evidence. First, explicit user feedback in the form of votes (e.g., “thumbs‑up” or “trust this code”) is collected for each project. Second, the cross‑project activity of each developer—measured by the number of commits, merged pull requests, and resolved issues across all open‑source repositories they have contributed to—is used as an indicator of sustained expertise and community impact.
A developer’s “karma” is computed by normalising both the vote count and the activity count with a logarithmic transformation to dampen extreme values, then weighting them with tunable parameters α and β:
K = α·log₁₀(V + 1) + β·log₁₀(A + 1).
The logarithmic scaling prevents a single highly‑voted project from dominating the score and yields a smoother distribution of karma values. The parameters can be adjusted per domain, allowing a security‑focused community to emphasise activity (β) while a data‑science community might give more weight to peer votes (α).
For a given project, the trustability score T is the weighted average of the karmas of all its contributors, where each contributor’s weight reflects their proportion of commits within that project. This formulation ensures that a project maintained by many high‑karma developers receives a high trustability rating, whereas a project dominated by a single low‑karma contributor is penalised.
To validate the concept, the authors built a prototype search engine called JBender. JBender reuses a standard Lucene‑based indexing pipeline but augments each search hit with the computed trustability score and a breakdown of the contributing developers’ karmas. Users can view these scores alongside traditional relevance rankings, filter results by a minimum trustability threshold, and inspect individual developer profiles to understand the provenance of the code.
The evaluation involved crawling roughly 500 open‑source projects and extracting activity data for over 2,000 developers. Three primary metrics were examined: (1) the post‑integration bug rate of selected code, (2) developers’ self‑reported willingness to reuse the code, and (3) the statistical correlation between trustability scores and observed quality outcomes. Results showed that code from the top‑20 % of trustability scores exhibited a 35 % reduction in bug introductions and a 27 % increase in reuse intent compared with lower‑scoring code. The Pearson correlation between trustability and bug rate was –0.48, indicating a moderate inverse relationship.
The study also acknowledges limitations. Vote data are sparse for new or niche projects, potentially under‑estimating their trustability. Moreover, the system is vulnerable to vote manipulation; the authors suggest future work on anomaly detection and reputation‑network analysis to mitigate this risk. Finally, applying the metric within corporate environments raises privacy concerns, prompting a need for anonymised or encrypted activity tracking.
In conclusion, the paper contributes a novel, developer‑centric trustability metric, demonstrates its feasibility through the JBender prototype, and provides empirical evidence that higher trustability correlates with better integration outcomes. Future research directions include refining the weighting scheme, incorporating temporal decay of karma, designing robust anti‑gaming mechanisms, and extending the approach to private codebases while preserving confidentiality.