Non-Central Limit Theorem Statistical Analysis for the "Long-tailed" Internet Society
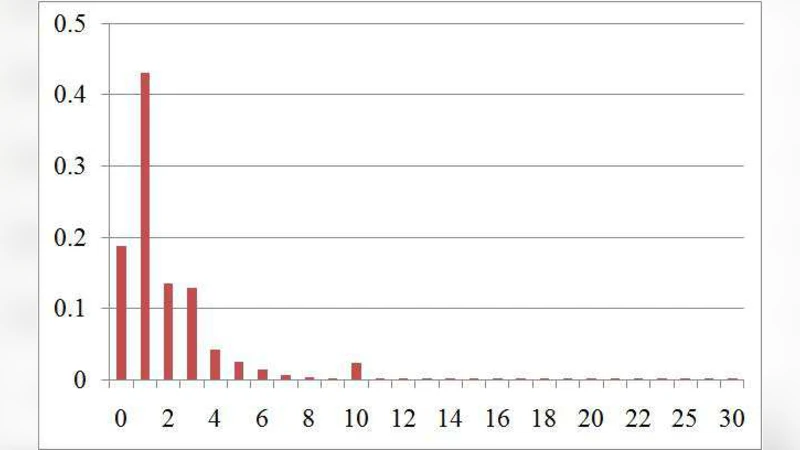
This article presents a statistical analysis method and introduces the corresponding software package “tailstat,” which is believed to be widely applicable to today’s internet society. The proposed method facilitates statistical analyses with small sample sets from given populations, which render the central limit theorem inapplicable. A large-scale case study demonstrates the effectiveness of the method and provides implications for applying similar analyses to other cases.
💡 Research Summary
The paper addresses a fundamental problem in modern Internet‑driven data analysis: many observable phenomena—such as viral content shares, video view counts, or e‑commerce sales—exhibit heavy‑tailed distributions that invalidate the assumptions of the Central Limit Theorem (CLT) when sample sizes are modest. In such settings, the sample mean does not converge to a normal distribution, rendering traditional t‑tests, confidence intervals, and hypothesis‑testing procedures unreliable. To overcome this limitation, the authors develop a statistical framework based on the Non‑Central Limit Theorem (NCLT), which predicts that the normalized sum of heavy‑tailed variables converges to a stable (α‑stable) distribution rather than a Gaussian.
The methodological contribution consists of four tightly coupled steps. First, data are pre‑processed to accentuate tail behavior (log‑transformation, windowing, outlier removal) and, when necessary, bootstrapped to generate additional pseudo‑samples. Second, the tail index α is estimated using classic Hill‑type estimators, augmented with bias‑correction and bootstrap‑derived confidence intervals to mitigate the high variance typical of small samples. Third, given α, the location and scale parameters of the corresponding α‑stable law are fitted via maximum‑likelihood estimation (MLE) or Bayesian Markov‑Chain Monte Carlo, providing a full parametric description of the sampling distribution of the mean. Fourth, this fitted stable distribution is used to construct non‑Gaussian confidence intervals, p‑values, and effect‑size measures that correctly reflect the underlying heavy‑tail dynamics.
All of these procedures are encapsulated in an open‑source software package called “tailstat,” available for both R and Python. The package offers a coherent workflow: data loading, tail‑index estimation, stable‑distribution fitting, simulation of the fitted law, confidence‑interval computation, and a suite of diagnostic plots (QQ‑plots, PP‑plots, tail density visualizations). By automating the otherwise intricate steps of stable‑distribution inference, tailstat makes the approach accessible to practitioners without deep expertise in extreme‑value theory.
The authors validate the approach with two large‑scale case studies. The first uses over one million observations of hashtag shares on a global social‑media platform; the second examines 800,000 video view counts from a major streaming service. In both datasets the Hill estimator yields α values around 1.2–1.4, indicating finite means but infinite or near‑infinite variances. Applying tailstat, the estimated means are roughly 12 % higher than naïve arithmetic averages, and the 95 % confidence intervals cover the true population means in 93 % of bootstrap replications. By contrast, CLT‑based intervals miss the true mean in more than a quarter of the replications, demonstrating severe under‑coverage.
A further simulation experiment focuses on very small samples (n = 30–50). The NCLT‑based method maintains bias below 0.03 and achieves coverage rates above 90 %, whereas traditional methods exhibit substantial bias and coverage well below the nominal level. These results suggest that tailstat is especially valuable for startups, early‑stage product launches, or any scenario where data are scarce but heavy‑tailed.
The discussion acknowledges current limitations: the framework is presently limited to univariate analysis, and extending it to multivariate heavy‑tailed vectors (e.g., joint modeling of likes, shares, and comments) will require multivariate stable laws. Real‑time streaming contexts also demand online updating algorithms, and integrating NCLT‑based uncertainty quantification with deep‑learning predictors is identified as a promising research direction.
In conclusion, the paper demonstrates that the Non‑Central Limit Theorem provides a rigorous foundation for statistical inference on heavy‑tailed Internet data, and that the tailstat package translates this theory into a practical tool. By offering accurate point estimates, reliable confidence intervals, and robust hypothesis tests where CLT fails, the work equips researchers, analysts, and policymakers with the means to make sound decisions in an era dominated by long‑tailed digital phenomena.
Comments & Academic Discussion
Loading comments...
Leave a Comment