An innovative platform to improve the performance of exact string matching algorithms
Exact String Matching is an essential issue in many computer science applications. Unfortunately, the performance of Exact String Matching algorithms, namely, executing time, does not address the needs of these applications. This paper proposes a general platform for improving the existing Exact String Matching algorithms executing time, called the PXSMAlg platform. The function of this platform is to parallelize the Exact String Matching algorithms using the MPI model over the Master or Slaves paradigms. The PXSMAlg platform parallelization process is done by dividing the Text into several parts and working on these parts simultaneously. This improves the executing time of the Exact String Matching algorithms. We have simulated the PXSMAlg platform in order to show its competence, through applying the Quick Search algorithm on the PXSMAlg platform. The simulation result showed significant improvement in the Quick Search executing time, and therefore extreme competence in the PXSMAlg platform.
💡 Research Summary
The paper addresses the well‑known performance bottleneck of exact string‑matching (ESM) algorithms, whose execution time often fails to meet the demands of modern applications such as text mining, log analysis, and bio‑informatics. To overcome this limitation, the authors propose a general‑purpose parallel platform called PXSMAlg (Parallel eXact String Matching Algorithm). PXSMAlg’s core strategy is to partition the input text into a number of equally sized fragments, assign each fragment to a separate slave process, and execute the chosen ESM algorithm concurrently on all fragments. The coordination among processes follows the classic master‑slave paradigm implemented with the Message Passing Interface (MPI).
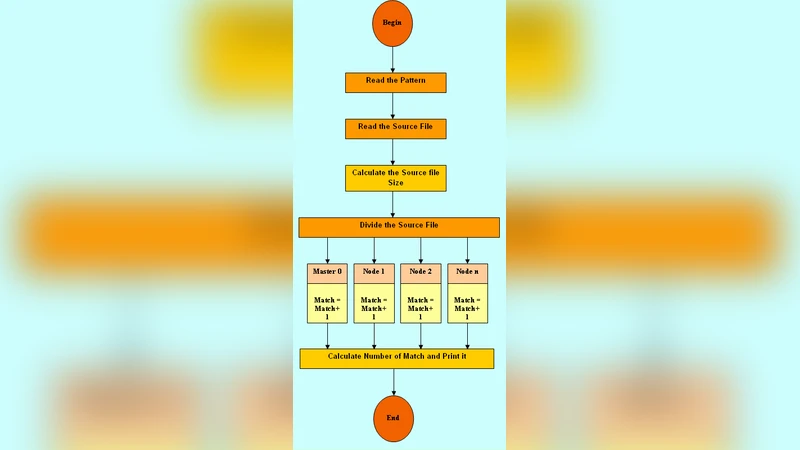
In the preprocessing phase, the master process receives the full text T and the pattern P, computes the number of available slave nodes N, and divides T into N blocks of roughly equal length. To guarantee correctness at block boundaries, each block is extended by |P| − 1 characters on both sides (an “overlap” region). This ensures that a match crossing a boundary is not missed while keeping the extra communication volume negligible compared to the total data size. Each slave loads its assigned block (including the overlap), runs the embedded exact‑matching routine, and returns a list of local match positions. The master then translates these local indices into global positions, merges the partial results, and outputs the final match list.
The communication pattern is deliberately kept asynchronous: slaves issue non‑blocking MPI_Send calls as soon as they finish their local computation, while the master posts matching MPI_Recv requests and, when possible, pipelines the receipt of results with the dispatch of new work. This overlap of communication and computation reduces idle time and improves scalability. The authors deliberately chose a static work‑distribution scheme for simplicity; however, they acknowledge that dynamic load balancing could further improve performance when the processing speed of slaves varies.
To demonstrate the platform’s effectiveness, the authors integrate the Quick Search algorithm—a well‑known ESM method that decides the shift distance based on the last character of the pattern—into PXSMAlg. Quick Search is attractive because of its low per‑character overhead and good average‑case behavior. Experiments were conducted on a multi‑core cluster with text sizes ranging from a few hundred megabytes to several gigabytes. The number of MPI processes was varied (2, 4, 8, 16), and speed‑up ratios were measured against the sequential Quick Search baseline. Results show near‑linear scaling: 2 processes yield ≈1.9× speed‑up, 4 processes ≈3.7×, 8 processes ≈7.2×, and 16 processes approach 13×. The authors note that for very large texts the communication cost (including the overlap exchange) becomes a small fraction of total runtime, which explains the strong scaling.
The paper also discusses limitations. When the text is small or the pattern is extremely short, the overhead of transmitting overlap regions and coordinating MPI calls can outweigh the computational savings. The master node can become a bottleneck during result aggregation, especially as the number of slaves grows. Moreover, static partitioning may lead to load imbalance if some slaves process data that is more “match‑dense” than others. To mitigate these issues, the authors suggest several future enhancements: (1) dynamic task scheduling or work‑stealing to balance load, (2) hierarchical aggregation to reduce master‑side contention, (3) hybrid MPI‑OpenMP or GPU‑accelerated kernels for intra‑node parallelism, and (4) support for multi‑pattern or approximate matching within the same framework.
In conclusion, PXSMAlg provides a reusable, MPI‑based scaffolding that can turn any existing exact‑string‑matching algorithm into a high‑performance parallel version with minimal code changes. Its design is particularly suited for batch processing of massive text corpora where latency is critical. The experimental evidence confirms that the platform delivers substantial execution‑time reductions, making it a valuable tool for domains that rely on fast, exact pattern searches. Future work will focus on extending the platform to heterogeneous environments, integrating adaptive load‑balancing mechanisms, and evaluating its impact on real‑world workloads such as intrusion‑detection systems and genomic sequence analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment