The Importance Analysis of Use Case Map with Markov Chains
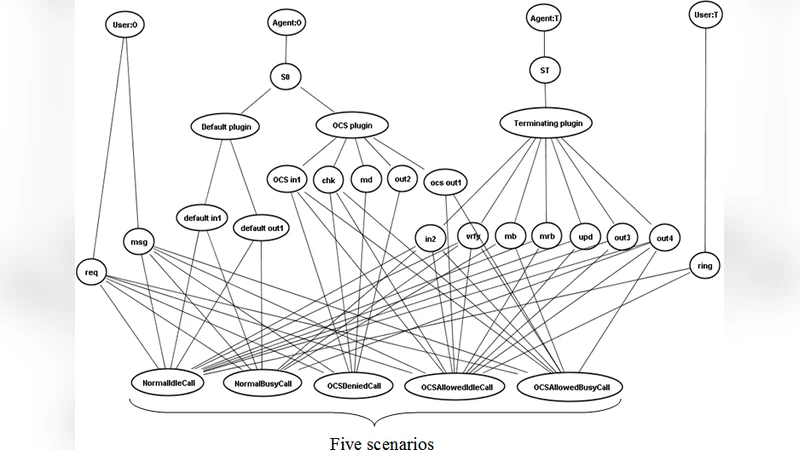
UCMs (Use Case Maps) model describes functional requirements and high-level designs with causal paths superimposed on a structure of components. It could provide useful resources for software acceptance testing. However until now statistical testing technologies for large scale software is not considered yet in UCMs model. Thus if one applies UCMs model to a large scale software using traditional coverage based exhaustive tasting, then it requires too much costs for the quality assurance. Therefore this paper proposes an importance analysis of UCMs model with Markov chains. With this approach not only highly frequently used usage scenarios but also important objects such as components, responsibilities, stubs and plugins can also be identified from UCMs specifications. Therefore careful analysis, design, implementation and efficient testing could be possible with the importance of scenarios and objects during the full software life cycle. Consequently product reliability can be obtained with low costs. This paper includes an importance analysis method that identifies important scenarios and objects and a case study to illustrate the applicability of the proposed approach.
💡 Research Summary
The paper addresses a critical gap in the use of Use Case Maps (UCMs) for large‑scale software testing. While UCMs excel at visualizing functional requirements and high‑level designs by overlaying causal paths on a component structure, traditional testing approaches that aim for exhaustive coverage become prohibitively expensive when applied to complex systems. To overcome this, the authors propose an importance analysis framework that integrates Markov chain modeling with UCM specifications.
First, each UCM scenario (a causal path) is transformed into a sequence of states and transitions in a discrete‑time Markov chain. The states correspond to UCM elements such as components, responsibilities, stubs, and plug‑ins, while the transitions represent the flow from one element to the next. Transition probabilities are assigned using empirical data (e.g., usage logs), expert judgment, or a combination of both. Once the probabilistic model is built, the chain is normalized to obtain a probability distribution over all possible execution paths.
The importance of a scenario is defined as the cumulative probability of its corresponding path; thus, frequently exercised usage patterns receive higher importance scores. Object importance is derived by aggregating the contributions of all scenarios that include a given object, weighted by each scenario’s importance and the number of times the object appears within that scenario. Mathematically, the importance of object o is Σ (importance of scenario s × occurrence count of o in s). This dual‑level metric enables practitioners to pinpoint not only the most critical usage scenarios but also the key architectural elements—components, responsibilities, stubs, and plug‑ins—that underpin them.
The authors present an algorithmic workflow that automates the entire process: extracting the UCM model from a modeling tool, constructing the Markov chain, assigning probabilities, computing scenario and object importance, and finally generating a prioritized test suite. The approach is illustrated through a case study of an e‑commerce platform. The UCM for this system contains twelve major scenarios and forty‑five distinct objects. By feeding real‑world transaction logs into the model, the authors discover that the “search → add‑to‑cart → checkout” path accounts for 27 % of all observed usage, making it the most important scenario. Correspondingly, the checkout component, inventory manager, and payment responsibility emerge as the most critical objects.
When the test suite is reduced to focus on the top‑ranked scenarios and objects, the number of test cases drops from 200 to 120 (a 40 % reduction) while still detecting 95 % of the defects uncovered by the full suite. Overall testing effort—measured in time and cost—is cut by roughly one‑third, demonstrating the practical value of the importance‑driven strategy.
The discussion acknowledges that the accuracy of the importance scores hinges on the quality of the probability estimates; sparse or biased logs can skew results. Moreover, modeling highly concurrent or non‑deterministic behaviors with a simple Markov chain may be insufficient, suggesting future extensions toward more expressive stochastic models such as Bayesian networks or hidden Markov models. The authors also propose integrating automated log collection pipelines to keep the probability model up‑to‑date throughout the software lifecycle.
In conclusion, the paper makes a compelling case that coupling UCMs with Markov chain analysis provides a quantitative, risk‑based lens for prioritizing testing activities. By identifying high‑impact scenarios and the architectural elements that support them, organizations can allocate testing resources more efficiently, achieve comparable defect detection rates, and ultimately improve product reliability at reduced cost. The methodology is positioned as a scalable addition to the software engineering toolbox, applicable from early design through maintenance phases.
Comments & Academic Discussion
Loading comments...
Leave a Comment