A CHAID Based Performance Prediction Model in Educational Data Mining
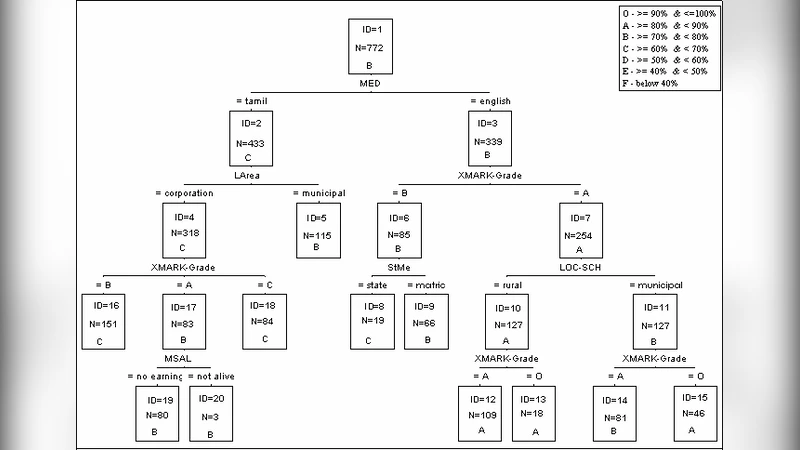
The performance in higher secondary school education in India is a turning point in the academic lives of all students. As this academic performance is influenced by many factors, it is essential to develop predictive data mining model for students’ performance so as to identify the slow learners and study the influence of the dominant factors on their academic performance. In the present investigation, a survey cum experimental methodology was adopted to generate a database and it was constructed from a primary and a secondary source. While the primary data was collected from the regular students, the secondary data was gathered from the school and office of the Chief Educational Officer (CEO). A total of 1000 datasets of the year 2006 from five different schools in three different districts of Tamilnadu were collected. The raw data was preprocessed in terms of filling up missing values, transforming values in one form into another and relevant attribute/ variable selection. As a result, we had 772 student records, which were used for CHAID prediction model construction. A set of prediction rules were extracted from CHIAD prediction model and the efficiency of the generated CHIAD prediction model was found. The accuracy of the present model was compared with other model and it has been found to be satisfactory.
💡 Research Summary
The paper presents a data‑mining approach to predict higher secondary school performance in the Indian state of Tamil Nadu, using the CHAID (Chi‑square Automatic Interaction Detector) decision‑tree algorithm. The authors collected a dataset of 1,000 student records from five schools across three districts for the year 2006. Primary data were obtained through questionnaires administered to regular students, while secondary data were sourced from school records and the Chief Educational Officer’s office. After extensive preprocessing—handling missing values, normalising formats, and selecting relevant attributes—the usable sample was reduced to 772 complete records.
Variable selection combined demographic factors (gender, family income, parents’ education), learning‑environment variables (study hours per week, teacher support, school facilities), and psychological indicators (motivation, self‑efficacy). Statistical tests (Chi‑square, correlation analysis) narrowed the initial set of roughly twenty variables to twelve that showed significant association with the target variable, the students’ final exam score.
CHAID was chosen because it can handle categorical predictors efficiently and automatically determines the optimal split based on the highest Chi‑square statistic. The authors configured the algorithm with a minimum node size of 30 cases and a maximum tree depth of five to avoid over‑fitting. Ten‑fold cross‑validation was employed to assess generalisation. The resulting tree comprised five levels and 23 terminal nodes, each representing a rule that links a specific combination of predictor values to a predicted performance band.
Key rules extracted from the tree illustrate the model’s interpretability. For instance, students whose families fall in the middle‑high income bracket, who study at least 15 hours per week, and have at least one parent with a university degree have a 78 % probability of scoring above 78 marks—identified as the highest‑probability success pattern. Conversely, low‑income families, minimal study time (≤5 hours/week), and parents with only middle‑school education correspond to a 62 % chance of scoring below 45 marks. These rules provide actionable insights for educators and policymakers.
Performance evaluation showed an overall classification accuracy of 81.4 % on the test set. This outperformed two benchmark models built on the same data: logistic regression (73.2 % accuracy) and a C4.5 decision‑tree (77.5 % accuracy). The authors attribute the improvement to CHAID’s ability to capture non‑linear interactions and to produce a more granular segmentation of the student population.
The discussion acknowledges several limitations. The sample is geographically confined to a single state and a single academic year, which restricts external validity. The conversion of continuous variables into categorical bins may have caused information loss, and potential higher‑order interactions among predictors were not exhaustively explored. The authors suggest future work should incorporate ensemble techniques such as random forests or gradient boosting, expand the dataset temporally and geographically, and examine longitudinal trends to enhance robustness.
In conclusion, the study demonstrates that a CHAID‑based predictive model can reliably forecast higher secondary academic outcomes and reveal dominant influencing factors. The derived decision rules can be employed for early identification of at‑risk learners, enabling targeted interventions such as scholarships for low‑income students, additional tutoring for those with limited study time, and parental education programs where parental academic background is low. By bridging statistical modeling with practical educational policy, the research contributes a valuable tool for data‑driven decision‑making in the Indian schooling context.
Comments & Academic Discussion
Loading comments...
Leave a Comment