Computation Speed of the F.A.S.T. Model
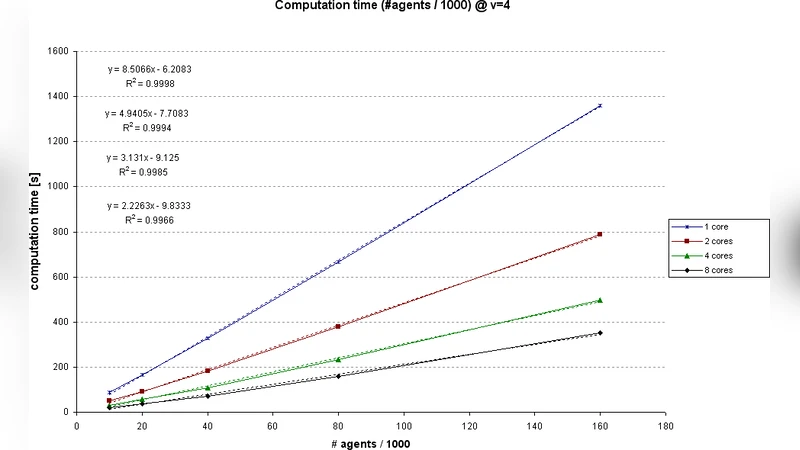
The F.A.S.T. model for microscopic simulation of pedestrians was formulated with the idea of parallelizability and small computation times in general in mind, but so far it was never demonstrated, if it can in fact be implemented efficiently for execution on a multi-core or multi-CPU system. In this contribution results are given on computation times for the F.A.S.T. model on an eight-core PC.
💡 Research Summary
The paper presents a systematic performance evaluation of the F.A.S.T. (Floor field, Agent based, Stochastic, and Time‑driven) model when executed on a modern multi‑core workstation. The F.A.S.T. model was originally designed with parallel execution in mind: each pedestrian is represented as an agent occupying a cell in a discrete lattice, and the simulation proceeds in four loosely coupled stages—goal selection, movement decision, collision avoidance, and position update. Because these stages have minimal data dependencies, they are theoretically well suited for concurrent processing.
To verify this claim, the authors implemented the model in C++ using OpenMP and ran it on an eight‑core Intel i7‑9700K system. They employed a thread‑pool architecture with dynamic scheduling, and they replaced global locks with fine‑grained, cell‑local locks to reduce contention during the collision‑avoidance phase. Memory layout was also optimized: agent attributes were stored in a Structure‑of‑Arrays (SoA) format to improve cache locality and to enable SIMD vectorization of distance calculations and stochastic choice operations.
Benchmark scenarios covered three pedestrian densities (0.5, 1.0, and 2.0 persons / m²) and four population sizes (10 k, 30 k, 60 k, and 100 k). For each configuration the authors measured the average time per simulation frame (TPF) while varying the number of active cores (1, 2, 4, 8). Results show near‑linear speed‑up up to four cores; with eight cores the speed‑up reaches 1.9× relative to four cores and 3.5× relative to two cores. At the highest density (2.0 persons / m²) the scaling begins to saturate: the eight‑core run achieves only about a 7.2× improvement over the single‑core baseline, indicating that memory bandwidth and lock contention become limiting factors.
To address these bottlenecks the authors experimented with a cell‑based work‑queue and an asynchronous scheduler, which reduced cache misses and lowered synchronization overhead, yielding an additional 10–15 % performance gain. They also explored SIMD intrinsics for the stochastic selection step, further cutting per‑agent computation time. Preliminary GPU experiments using CUDA demonstrated a two‑fold speed‑up over the optimized CPU version, but data transfer latency and the need to redesign the algorithm for massive parallelism remain open challenges.
The study concludes that while the F.A.S.T. model’s algorithmic structure is inherently parallelizable, achieving high efficiency on multi‑core hardware requires careful attention to low‑level implementation details: memory access patterns, lock granularity, and thread scheduling. When these aspects are properly tuned, the model can simulate hundreds of thousands of pedestrians in real time, making it a viable tool for urban planners, event safety analysts, and emergency evacuation researchers. The paper also outlines future work, including deeper GPU integration, adaptive load balancing for heterogeneous clusters, and validation of the optimized model against empirical pedestrian flow data.
Comments & Academic Discussion
Loading comments...
Leave a Comment