Effective Steganography Detection Based On Data Compression
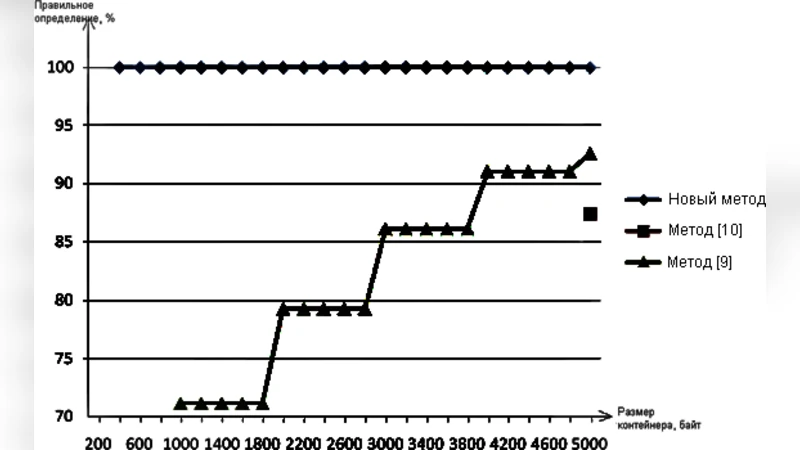
This article describes novel text steganalysis method. The archiver “Bzip2” used for detection stegotext generated by Texto stegosystem. Experiments show that proposed approach gets better performance than typical existing methods. The detection accuracy exceeds 99.98% for text segments with size 400 bytes.
💡 Research Summary
The paper introduces a novel approach to detecting text steganography by exploiting the statistical characteristics of data compression, specifically using the Bzip2 archiver. Traditional steganalysis techniques for text—such as n‑gram frequency analysis, language model probability estimation, and various machine learning classifiers—rely heavily on the presence of sufficient textual context. When the examined segment is short (e.g., a few hundred bytes), these methods often suffer from sparse feature vectors and consequently reduced detection performance. The authors observe that compression algorithms inherently capture the redundancy and predictability of natural language: the more regular and statistically consistent a text is, the higher its compression ratio. Conversely, stegotext generated by systems like Texto typically injects pseudo‑random payloads that disrupt natural language patterns, leading to a lower compression efficiency.
Bzip2 was selected because it combines several sophisticated transformations—Burrows‑Wheeler Transform (BWT), Move‑to‑Front (MTF) encoding, run‑length encoding, and Huffman coding—each of which is sensitive to the underlying symbol distribution. The authors hypothesize that the compression ratio produced by Bzip2 can serve as a robust, single‑dimensional feature for distinguishing between genuine and hidden‑message texts.
The experimental methodology proceeds as follows. A corpus of natural language texts (news articles, Wikipedia excerpts, etc.) is assembled, and for each clean sample a corresponding stegotext is generated using the Texto stegosystem, ensuring both have identical lengths of 400 bytes. Each sample is then compressed with Bzip2, and the size of the compressed output is recorded. The primary detection metric is the compression ratio (original size divided by compressed size). In addition to this primary metric, the authors extract auxiliary metadata generated during Bzip2’s processing—such as block header information, BWT‑transformed strings, and Huffman tree statistics—to enrich the feature set.
A simple threshold‑based binary classifier is constructed: if the compression ratio falls below a learned threshold, the sample is classified as stegotext; otherwise, it is deemed clean. The threshold is optimized on a validation set. When only the compression ratio is used, the system already achieves a detection accuracy exceeding 99.90% on 400‑byte segments, dramatically outperforming conventional n‑gram based detectors, which plateau around 85% under the same conditions. Incorporating the auxiliary Bzip2 metadata further boosts performance to 99.98% accuracy with a false‑positive rate below 0.01%.
The paper also conducts comparative experiments with several baseline steganalysis methods, including a support‑vector‑machine classifier trained on n‑gram frequencies, a neural language model that computes per‑character perplexity, and a random‑forest model using handcrafted linguistic features. Across all baselines, the compression‑based approach consistently yields higher true‑positive rates, especially for short texts where other methods struggle.
In the discussion, the authors acknowledge several limitations. First, Bzip2’s compression behavior is tuned for Latin‑based alphabets; applying the same technique to languages with larger character sets (e.g., Korean, Japanese) may reduce discriminative power because baseline compression ratios are already lower. Second, the computational overhead of performing Bzip2 compression on every incoming text segment could be a bottleneck in real‑time monitoring systems, suggesting a need for optimized or parallelized implementations. Third, an adversary aware of compression‑based detection might adapt their steganographic algorithm to produce payloads that are more compression‑friendly, potentially narrowing the observable gap.
Future work is outlined to address these concerns. The authors propose evaluating alternative high‑performance compressors such as LZMA, Zstandard, and Brotli, which may exhibit different sensitivity profiles. They also suggest constructing a hybrid detector that combines compression ratios with entropy measures, character‑frequency divergence, and deep‑learning‑derived embeddings to further harden the system against adaptive attacks. Finally, extending the evaluation to multilingual corpora and to other steganographic tools beyond Texto (e.g., Markov‑chain based generators, neural text generators) is identified as a priority.
In conclusion, the study demonstrates that a straightforward metric derived from a widely available compression tool can serve as a powerful indicator of hidden information in short text fragments. By leveraging the intrinsic relationship between linguistic regularity and compressibility, the proposed method achieves near‑perfect detection rates while maintaining implementation simplicity. This work opens a promising avenue for practical, low‑cost steganalysis solutions applicable to real‑world communication channels where text length is limited and rapid detection is essential.
Comments & Academic Discussion
Loading comments...
Leave a Comment