Introduction to Distributed Systems
Computing has passed through many transformations since the birth of the first computing machines. Developments in technology have resulted in the availability of fast and inexpensive processors, and progresses in communication technology have resulted in the availability of lucrative and highly proficient computer networks. Among these, the centralized networks have one component that is shared by users all the time. All resources are accessible, but there is a single point of control as well as a single point of failure. The integration of computer and networking technologies gave birth to new paradigm of computing called distributed computing in the late 1970s. Distributed computing has changed the face of computing and offered quick and precise solutions for a variety of complex problems for different fields. Nowadays, we are fully engrossed by the information age, and expending more time communicating and gathering information through the Internet. The Internet keeps on progressing along more than a few magnitudes, abiding end systems increasingly to communicate in more and more different ways. Over the years, several methods have evolved to enable these developments, ranging from simplistic data sharing to advanced systems supporting a multitude of services. This article provides an overview of distributed computing systems. The definition, architecture, characteristics of distributed systems and the various distributed computing fallacies are discussed in the beginning. Finally, discusses client/server computing, World Wide Web and types of distributed systems.
💡 Research Summary
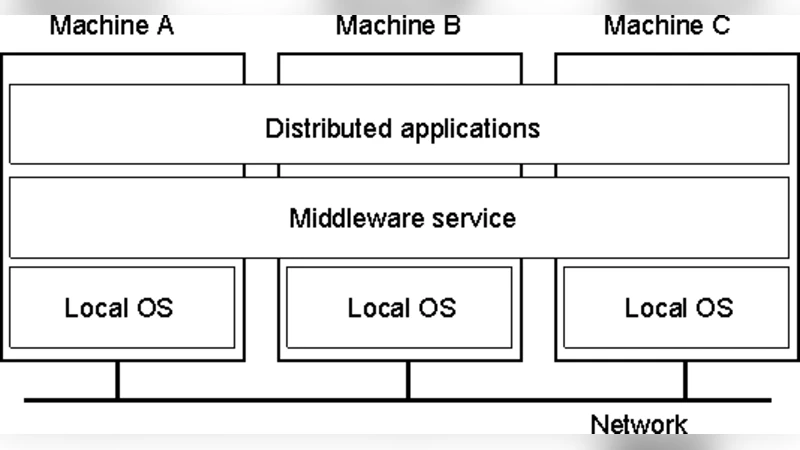
The paper provides a comprehensive introductory overview of distributed computing, tracing its evolution from the early days of centralized mainframe systems to the modern, highly networked environment. It begins by highlighting the limitations of centralized architectures—namely a single point of control and a single point of failure—while noting that advances in processor speed, cost reduction, and communication technologies in the 1970s paved the way for the emergence of distributed systems. The authors define a distributed system as a collection of independent computers that cooperate to appear as a single coherent entity to the user, emphasizing that this abstraction hides the underlying heterogeneity of hardware, operating systems, and network topologies.
Four fundamental characteristics of distributed systems are discussed in depth: transparency, scalability, reliability, and resource sharing. Transparency ensures that users are unaware of the physical location or implementation details of resources, providing a seamless experience. Scalability refers to the ability to increase processing power and storage capacity linearly by adding nodes, which is essential for handling growth in demand. Reliability is achieved through replication, fault‑tolerant protocols, and multiple communication paths, mitigating the risks associated with individual node failures. Resource sharing enables heterogeneous platforms to exchange data and services, reducing overall cost and improving utilization.
A central part of the paper is devoted to the “distributed computing fallacies,” a set of eight common misconceptions that can lead to design failures: (1) the network is reliable, (2) bandwidth is infinite, (3) latency is negligible, (4) security is automatically guaranteed, (5) the system is easy to manage, (6) transport cost is zero, (7) concurrency problems disappear, and (8) replication and consistency incur no overhead. The authors argue that ignoring these fallacies results in performance bottlenecks, data inconsistency, security vulnerabilities, and unmanageable complexity.
The architectural discussion starts with the classic client‑server model, where clients issue requests and servers process them. While this model offers clear separation of concerns and easier maintenance, it suffers from potential overload of a single server. To address this, the paper describes multi‑tier (three‑tier or N‑tier) architectures that introduce load balancers, proxy servers, and additional application layers, thereby improving load distribution, fault tolerance, and security.
The World Wide Web is presented as the most ubiquitous example of a distributed system. Web browsers (clients) and web servers communicate via HTTP, enabling global information exchange. The authors note the evolution from static HTML pages to dynamic content, web services, and cloud‑based platforms, each adding layers of complexity that require more sophisticated distributed designs.
The paper categorizes distributed systems into four major types:
- Distributed File Systems – Provide transparent access to files stored across multiple nodes, supporting high availability and large‑scale data storage.
- Distributed Databases – Offer query processing over partitioned data while maintaining consistency guarantees; the discussion references the CAP theorem and various consistency models (strong, eventual, etc.).
- Distributed Object Systems – Enable remote method invocation (RMI), CORBA, gRPC, and similar mechanisms that extend object‑oriented programming across network boundaries.
- Distributed Computing Frameworks – Focus on parallel execution of tasks across many processors, exemplified by MapReduce, Apache Spark, and MPI. Each category is associated with specific protocols, consistency mechanisms, and fault‑recovery strategies.
In the concluding section, the authors stress that distributed systems are the backbone of contemporary IT infrastructure, underpinning cloud computing, the Internet of Things (IoT), and emerging edge‑computing paradigms. They advocate for a balanced design approach that simultaneously addresses transparency, scalability, and reliability while consciously avoiding the listed fallacies. By doing so, engineers and researchers can build robust, efficient, and adaptable distributed platforms capable of meeting the ever‑growing demands of the information age.
Comments & Academic Discussion
Loading comments...
Leave a Comment