Similarity Measures, Author Cocitation Analysis, and Information Theory
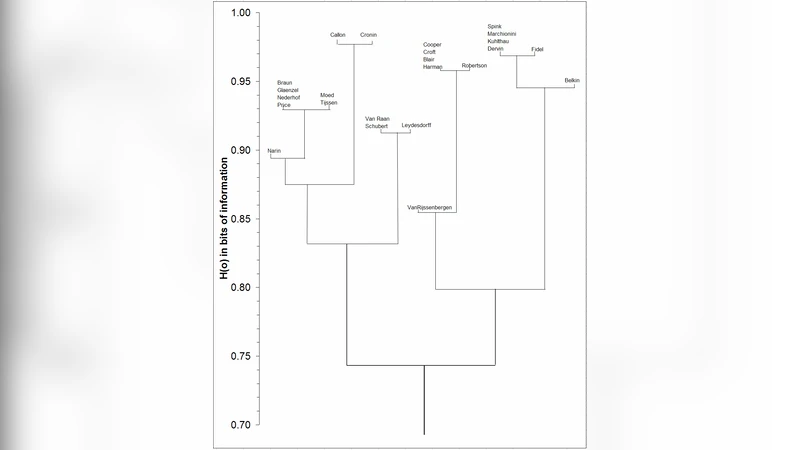
The use of Pearson’s correlation coefficient in Author Cocitation Analysis was compared with Salton’s cosine measure in a number of recent contributions. Unlike the Pearson correlation, the cosine is insensitive to the number of zeros. However, one has the option of applying a logarithmic transformation in correlation analysis. Information calculus is based on both the logarithmic transformation and provides a non-parametric statistics. Using this methodology one can cluster a document set in a precise way and express the differences in terms of bits of information. The algorithm is explained and used on the data set which was made the subject of this discussion.
💡 Research Summary
This paper revisits the core methodological choice in Author Cocitation Analysis (ACA)—the metric used to quantify similarity between authors—and proposes a novel, information‑theoretic approach that overcomes the shortcomings of the two most frequently employed measures, Pearson’s correlation coefficient and Salton’s cosine similarity.
The authors begin by outlining the theoretical and practical differences between Pearson’s r and the cosine. Pearson’s r treats the cocitation counts as continuous variables and captures linear relationships, but it is highly sensitive to the prevalence of zero entries that dominate most cocitation matrices. When many zeros are present, r can be artificially deflated, leading to misleading similarity scores and fragmented clusters. The cosine, by contrast, normalizes each author’s vector to unit length and therefore ignores the magnitude of the counts; it is robust to sparsity but cannot distinguish between authors who are cited frequently and those who are cited rarely if their citation patterns are directionally similar. Consequently, both measures either over‑penalize sparsity (Pearson) or under‑represent citation intensity (cosine).
To address these issues, the paper introduces a logarithmic transformation of the raw cocitation frequencies. By applying log‑base‑2 (or any monotonic log) to each cell, the authors compress the dynamic range of the data, reducing the impact of extreme values while preserving the order of magnitude relationships. Importantly, the log transformation also converts the count matrix into a probability distribution after normalization, which is a prerequisite for applying information theory.
The central contribution is the “information calculus” framework. After log‑transforming and normalizing the cocitation matrix, each cell becomes a joint probability P(i, j) for author i and author j. Marginal probabilities P(i·) and P(·j) are derived by summing over rows and columns, respectively. The mutual information (or pointwise mutual information) between two authors is then computed as
I(i; j) = log₂
Comments & Academic Discussion
Loading comments...
Leave a Comment