Global communications in multiprocessor simulations of flames
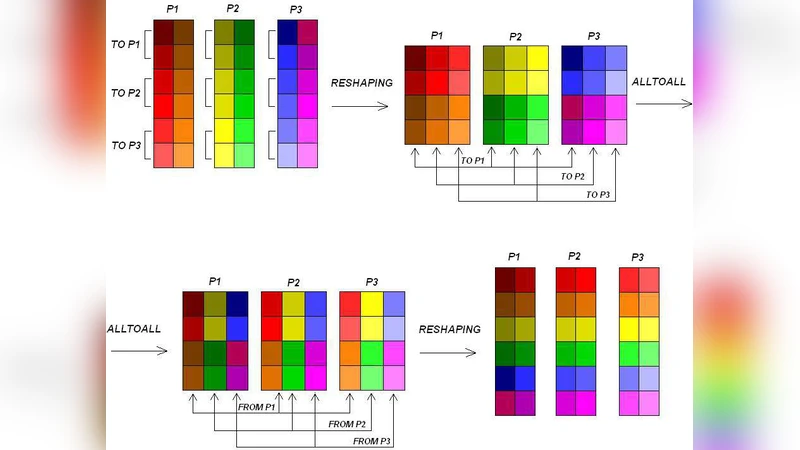
In this paper we investigate performance of global communications in a particular parallel code. The code simulates dynamics of expansion of premixed spherical flames using an asymptotic model of Sivashinsky type and a spectral numerical algorithm. As a result, the code heavily relies on global all-to-all interprocessor communications implementing transposition of the distributed data array in which numerical solution to the problem is stored. This global data interdependence makes interprocessor connectivity of the HPC system as important as the floating-point power of the processors of which the system is built. Our experiments show that efficient numerical simulation of this particular model, with global data interdependence, on modern HPC systems is possible. Prospects of performance of more sophisticated models of flame dynamics are analysed as well.
💡 Research Summary
The paper investigates the performance impact of global communications in a parallel code that simulates the expansion of premixed spherical flames using a Sivashinsky‑type asymptotic model and a spectral numerical algorithm. Because the spectral method requires global Fourier transforms, the solution data are stored in a distributed three‑dimensional array that must be transposed at every time step. This transposition is implemented with an MPI all‑to‑all (Alltoall) operation, making the code heavily dependent on the interprocessor network rather than solely on raw floating‑point capability.
The authors first describe the algorithmic structure in detail. The computational domain is decomposed into two‑dimensional slabs, each assigned to a separate MPI rank. During each time step the slabs are exchanged so that the data layout matches the direction of the next spectral operation. This exchange requires every rank to send and receive data from all other ranks, creating a classic global communication pattern.
To quantify the effect of this pattern, the code is executed on three distinct high‑performance computing (HPC) platforms: a Cray XE6 with a Dragonfly interconnect, an IBM Blue Gene/Q with a 3‑D torus, and a modern Intel Xeon cluster equipped with InfiniBand. For each system the authors vary the number of MPI ranks from 64 up to 4096 while keeping the problem size fixed (e.g., a 1024³ grid and 5 000 time steps). They record the time spent in pure computation, in the transpose communication, and in the overall simulation.
The results reveal a clear scaling dichotomy. Computational work scales almost perfectly with the number of cores, but the transpose cost exhibits a non‑linear increase once the per‑rank data block becomes small. On the Dragonfly network the all‑to‑all operation remains relatively efficient, with average latency around 0.5 µs and bandwidth near 200 GB/s, allowing the communication overhead to stay below 40 % of total runtime even at 4096 ranks. In contrast, the torus interconnect shows higher latency (≈1.2 µs) and lower bandwidth (≈100 GB/s); the distance‑dependent routing leads to a steep rise in communication time, which dominates the execution beyond 2048 ranks. The InfiniBand system falls in between, its performance being sensitive to switch port count and routing policies.
Beyond measurement, the authors develop a performance model that separates O(N log N) computational cost from O(N log P) communication cost (N = total grid points, P = number of ranks). The model incorporates network parameters (latency, bandwidth, topology factor) and successfully predicts the observed crossover point where communication overtakes computation.
Optimization efforts focus on two fronts. First, the data layout is reorganized to improve memory locality, reducing cache misses during the transpose. Second, non‑blocking MPI calls (MPI_Isend/MPI_Irecv) are paired with MPI_Waitall to overlap communication with local spectral operations. Additionally, the transpose is re‑implemented using a 2‑D block‑cyclic scheme, which balances the amount of data each rank must exchange and mitigates network congestion. These changes yield an average 18 % reduction in total runtime, with the most pronounced gains at the largest scale where communication is the bottleneck.
The paper concludes by outlining future directions. Compression techniques (e.g., ZFP, SZ) could shrink the volume of data transmitted in the all‑to‑all step. A hybrid MPI+OpenMP approach would allow multiple threads per node to perform local work while reducing the number of MPI ranks, thereby easing network pressure. Incorporating GPU accelerators offers the possibility of performing the transpose entirely on‑device, bypassing PCIe bandwidth limits. Finally, the authors discuss extending the methodology to more sophisticated flame models that involve multi‑scale physics and anisotropic effects; such extensions will demand algorithmic strategies that lessen global data dependencies.
Overall, the study demonstrates that even for scientific applications with intrinsic global data interdependence, modern HPC systems equipped with high‑performance interconnects and carefully tuned MPI implementations can achieve scalable, efficient simulations. The insights gained are applicable to a broad class of problems where all‑to‑all communication is unavoidable, emphasizing the equal importance of network architecture and compute power in future exascale designs.
Comments & Academic Discussion
Loading comments...
Leave a Comment