Reduce and Boost: Recovering Arbitrary Sets of Jointly Sparse Vectors
The rapid developing area of compressed sensing suggests that a sparse vector lying in an arbitrary high dimensional space can be accurately recovered from only a small set of non-adaptive linear measurements. Under appropriate conditions on the measurement matrix, the entire information about the original sparse vector is captured in the measurements, and can be recovered using efficient polynomial methods. The vector model has been extended to a finite set of sparse vectors sharing a common non-zero location set. In this paper, we treat a broader framework in which the goal is to recover a possibly infinite set of jointly sparse vectors. Extending existing recovery methods to this model is difficult due to the infinite structure of the sparse vector set. Instead, we prove that the entire infinite set of sparse vectors can recovered by solving a single, reduced-size finite-dimensional problem, corresponding to recovery of a finite set of sparse vectors. We then show that the problem can be further reduced to the basic recovery of a single sparse vector by randomly combining the measurement vectors. Our approach results in exact recovery of both countable and uncountable sets as it does not rely on discretization or heuristic techniques. To efficiently recover the single sparse vector produced by the last reduction step, we suggest an empirical boosting strategy that improves the recovery ability of any given sub-optimal method for recovering a sparse vector. Numerical experiments on random data demonstrate that when applied to infinite sets our strategy outperforms discretization techniques in terms of both run time and empirical recovery rate. In the finite model, our boosting algorithm is characterized by fast run time and superior recovery rate than known popular methods.
💡 Research Summary
The paper addresses the challenging problem of recovering an infinite collection of jointly sparse vectors, a setting that extends the traditional compressed sensing (CS) framework beyond the well‑studied single‑measurement‑vector (SMV) and finite‑multiple‑measurement‑vector (MMV) models. The authors introduce the Infinite Measurement Vectors (IMV) model, where a possibly countable or uncountable index set Λ parametrizes a family of vectors x(λ) that all share the same support I of size at most K. They first establish uniqueness conditions: using the Kruskal‑rank σ(A) of the sensing matrix A, they prove that a K‑sparse IMV solution is unique if σ(A) ≥ 2K − (dim(span y(Λ)) − 1). This relaxes the classic σ(A) ≥ 2K requirement for SMV because the joint sparsity reduces the effective degrees of freedom.
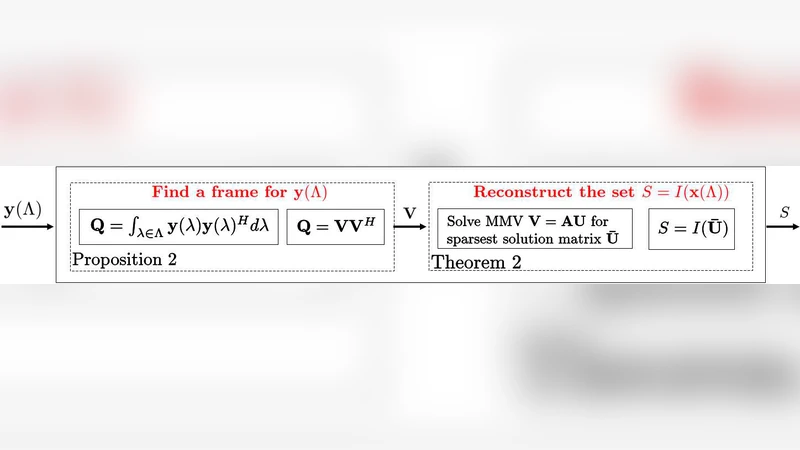
Next, the authors present a deterministic reduction that converts the infinite‑dimensional IMV problem into a finite‑dimensional MMV problem. By selecting a finite subset ˜Λ of Λ whose measurement vectors y(λ) are linearly independent (the number of selected indices equals r = dim(span y(Λ))), they obtain a standard MMV system Y = AX with the same unknown support I. This step avoids any discretization of the parameter space and guarantees that solving the MMV problem yields the exact support of the original infinite set.
The paper then introduces a probabilistic reduction from MMV to SMV. Random coefficients w∈ℝ^r are drawn from a continuous distribution and used to form a single combined measurement ỹ = ∑_i w_i y_i and a combined sensing matrix à = ∑_i w_i a_i (where a_i are the columns of A). The authors prove that, with probability one, the support I is preserved under this random linear combination, so the resulting SMV problem ỹ = à x̃ contains the same sparsity pattern as the original MMV system.
Because most practical sparse‑recovery algorithms (e.g., Basis Pursuit, Orthogonal Matching Pursuit) are sub‑optimal and their performance can depend on the actual non‑zero values, the authors propose a boosting strategy. They repeat the random combination step T times, each time solving the SMV problem with a chosen sub‑optimal algorithm. The support estimates from the T trials are then aggregated (e.g., by majority voting or intersection) to produce a final support estimate. This “ReMBo” (Reduction of MMV and Boosting) algorithm dramatically improves the probability of correctly identifying I while keeping computational cost low.
Extensive numerical experiments compare ReMBo against traditional discretization approaches and against state‑of‑the‑art MMV algorithms. The results show that ReMBo achieves exact support recovery for both countable and uncountable IMV instances with significantly lower run‑time than grid‑based methods, and it outperforms popular MMV techniques (such as Simultaneous OMP) in both recovery rate and speed. The boosting component is shown to converge rapidly: a modest number of repetitions (e.g., T ≈ 10–20) already yields recovery probabilities above 95 %.
In summary, the paper contributes (1) a novel uniqueness condition for infinite jointly sparse models, (2) a deterministic reduction from IMV to MMV, (3) a probabilistic reduction from MMV to SMV that preserves the support with probability one, and (4) a practical boosting scheme that enhances any sub‑optimal SMV solver. Together, these ideas provide a complete, exact, and computationally efficient pipeline for recovering arbitrary sets of jointly sparse vectors, opening the door to applications such as multi‑band analog signal reconstruction, magnetoencephalography, and sparse channel estimation.
Comments & Academic Discussion
Loading comments...
Leave a Comment