Network model of human language
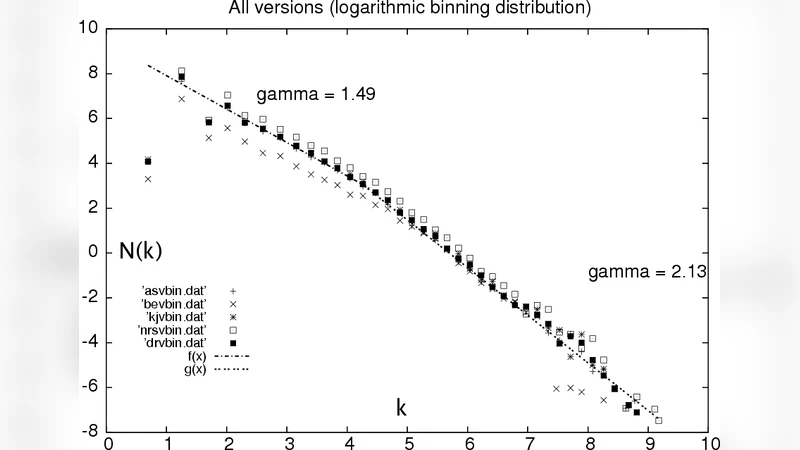
The phenomenon of human language is widely studied from various points of view. It is interesting not only for social scientists, antropologists or philosophers, but also for those, interesting in the network dynamics. In several recent papers word web, or language as a graph has been investigated. In this paper I revise recent studies of syntactical word web. I present a model of growing network in which such processes as node addition, edge rewiring and new link creation are taken into account. I argue, that this model is a satisfactory minimal model explaining measured data.
💡 Research Summary
The paper treats human language as a complex network of words, where each word is a node and co‑occurrence or syntactic relations are edges. After reviewing earlier work on “word webs,” the author points out that simple preferential‑attachment models (e.g., the Barabási‑Albert model) cannot reproduce the full set of empirical regularities observed in real linguistic corpora: a power‑law degree distribution together with a high clustering coefficient and a modular community structure. To address this gap, the author proposes a minimal yet richer growth model that incorporates three concurrent processes: (1) node addition with preferential attachment, representing the introduction of new words that tend to link to already frequent words; (2) edge rewiring, which randomly disconnects existing links and reconnects them to different nodes, mimicking semantic shift, changes in usage frequency, or cultural influences that remodel existing relationships; and (3) creation of new edges between already existing nodes, reflecting the emergence of novel syntactic or semantic associations.
Mathematically, each process is governed by a probability parameter (p_add, p_rewire, p_newlink). At each discrete time step a new node may be added, a fraction of existing edges may be rewired, and additional edges may be inserted between existing nodes. The evolution of the network is described as a discrete‑time Markov chain, allowing analytical derivation of expected degree distribution, average degree, clustering coefficient, average shortest‑path length, and modularity.
The model is calibrated and validated against several large‑scale corpora, including the English Wikipedia dump, a collection of English novels, and a Korean news corpus. Simulations show that the degree distribution retains a power‑law tail while the rewiring and new‑link mechanisms lift the low‑degree region, reproducing the “fat‑tail” shape seen in empirical data. The clustering coefficient rises with increasing p_newlink, and higher p_rewire values generate stronger community structure, matching the observed modularity of real word networks. The average shortest‑path length remains short, confirming the small‑world property. Sensitivity analysis demonstrates that varying p_rewire can model rapid semantic reorganization (e.g., the spread of neologisms), whereas low p_newlink yields sparser, more tree‑like structures akin to specialized jargon.
The discussion acknowledges limitations: the current formulation treats the network as undirected and unweighted, ignoring directionality (e.g., head‑dependent relations) and edge strength (frequency of co‑occurrence). It also omits multilayer aspects such as synonym/antonym relations or syntactic hierarchies. Future work is suggested to extend the model to weighted, directed, and multilayer networks, and to incorporate cross‑language interactions and sociolinguistic factors.
In conclusion, the paper presents a concise yet powerful model that captures the dynamic growth, rewiring, and link‑creation processes underlying language evolution. By reproducing key statistical signatures of empirical word webs, the model bridges a gap between pure network theory and linguistic reality, offering a useful framework for researchers in computational linguistics, complex systems, and data‑driven language studies.
Comments & Academic Discussion
Loading comments...
Leave a Comment