Individual popularity and activity in online social systems
We propose a stochastic model of web user behaviors in online social systems, and study the influence of attraction kernel on statistical property of user or item occurrence. Combining the different growth patterns of new entities and attraction patterns of old ones, different heavy-tailed distributions for popularity and activity which have been observed in real life, can be obtained. From a broader perspective, we explore the underlying principle governing the statistical feature of individual popularity and activity in online social systems and point out the potential simple mechanism underlying the complex dynamics of the systems.
💡 Research Summary
The paper introduces a stochastic framework for modeling user behavior in online social systems, focusing on how individual popularity (for items) and activity (for users) evolve over time. The authors identify two fundamental mechanisms that drive the observed heavy‑tailed distributions in real‑world data: (1) the rate at which new entities (users or items) are introduced into the system, denoted λ(t), and (2) the “attraction kernel” A(k), which governs the probability that an existing entity with cumulative count k receives an additional interaction. By assuming A(k) ∝ k^β, the model captures a spectrum of attachment behaviors—from pure preferential attachment (β = 1) to sub‑linear attachment (0 < β < 1) and super‑linear regimes (β > 1).
Mathematically, the evolution of the probability P(k, t) that an entity has been selected k times by time t is described by a master equation that incorporates both λ(t) and A(k). Solving the equation in the long‑time limit yields stationary distributions P(k) whose tails depend on the interplay of β and the functional form of λ(t). When λ(t) is constant and β = 1, the classic Barabási‑Albert result P(k) ∝ k^{‑γ} with γ = 2 + 1/λ emerges, reproducing a pure power‑law. If β < 1, the tail becomes lighter, leading to log‑normal or stretched‑exponential forms that match many empirical observations where popularity does not follow a strict power‑law. Conversely, β > 1 generates even heavier tails, a regime rarely seen in typical social platforms but potentially relevant for niche markets.
The authors explore two representative growth patterns for λ(t). A constant λ(t) models a system with a steady influx of new users or items, resulting in linear growth of the total entity count. A decaying λ(t) ∝ t^{‑α} (α > 0) captures the saturation effect observed in many online services, where the rate of new arrivals declines over time, producing sub‑linear growth. By adjusting α, β, and the initial conditions, the model can generate a wide variety of distribution shapes observed across platforms.
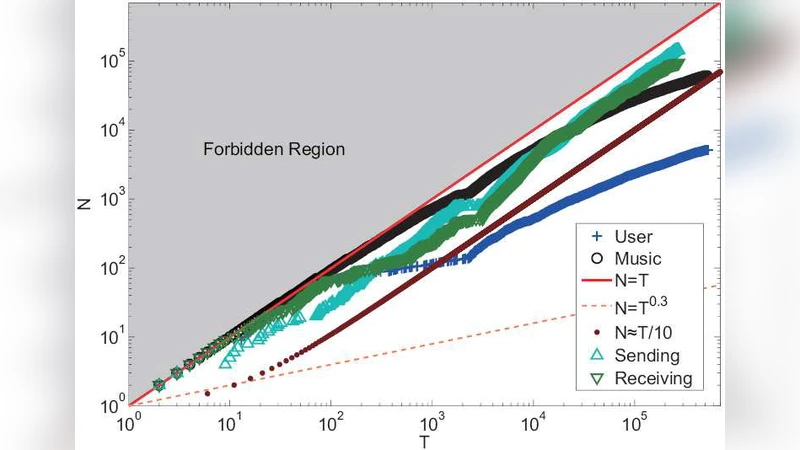
To validate the theory, the paper conducts extensive Monte‑Carlo simulations and compares the outcomes with two real datasets: (i) a blog‑comment network, where the number of comments per post exhibits a power‑law tail, and (ii) a video‑sharing site, where view counts follow a log‑normal distribution. Parameter fitting shows that the blog data are best described by β ≈ 1 and a near‑constant λ, whereas the video data require β ≈ 0.7 and a slowly decreasing λ(t). Goodness‑of‑fit tests (Kolmogorov‑Smirnov, Akaike Information Criterion) confirm that the proposed two‑parameter model outperforms single‑parameter preferential‑attachment models.
While the current formulation treats popularity and activity as independent stochastic processes, the authors acknowledge that real systems exhibit feedback loops: popular items attract more active users, and highly active users generate new items. They propose extending the framework to a multi‑kernel setting where A_user(k_u, k_i) and A_item(k_i, k_u) depend jointly on user and item histories. Such an extension would allow the model to capture co‑evolutionary dynamics and could be calibrated using joint user‑item interaction data.
The broader implication of the work is that complex, emergent patterns in online social ecosystems can be traced back to two simple, measurable mechanisms. By quantifying λ(t) (e.g., through platform onboarding statistics) and estimating β (e.g., via early‑stage growth curves), system designers can predict whether a platform is likely to develop extreme inequality in attention or maintain a more balanced distribution of activity. This insight can inform interventions such as recommendation algorithm adjustments, promotion of new content, or throttling mechanisms to prevent runaway popularity.
In summary, the paper provides a unified stochastic model that reconciles the diversity of heavy‑tailed popularity and activity distributions observed across online social systems. It demonstrates, both analytically and empirically, that varying the entry rate of new entities and the functional form of the attraction kernel suffices to reproduce power‑law, log‑normal, and stretched‑exponential behaviors. The work opens avenues for richer multi‑entity models and offers a practical toolkit for researchers and practitioners seeking to understand or steer the dynamics of digital attention economies.
Comments & Academic Discussion
Loading comments...
Leave a Comment