Beyond word frequency: Bursts, lulls, and scaling in the temporal distributions of words
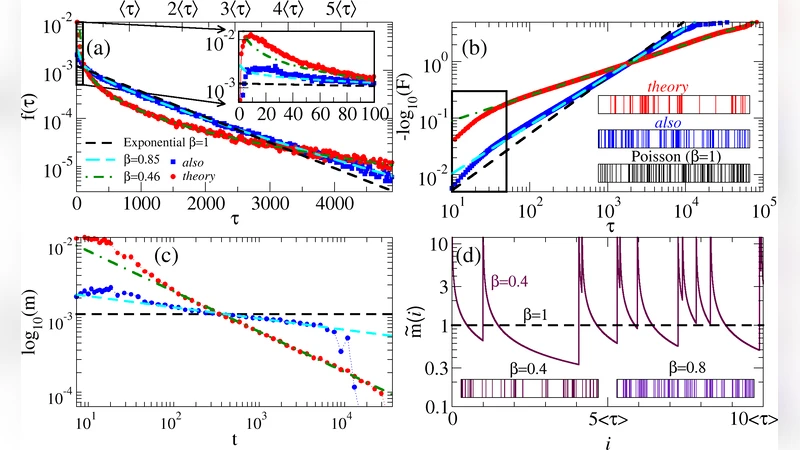
Background: Zipf’s discovery that word frequency distributions obey a power law established parallels between biological and physical processes, and language, laying the groundwork for a complex systems perspective on human communication. More recent research has also identified scaling regularities in the dynamics underlying the successive occurrences of events, suggesting the possibility of similar findings for language as well. Methodology/Principal Findings: By considering frequent words in USENET discussion groups and in disparate databases where the language has different levels of formality, here we show that the distributions of distances between successive occurrences of the same word display bursty deviations from a Poisson process and are well characterized by a stretched exponential (Weibull) scaling. The extent of this deviation depends strongly on semantic type – a measure of the logicality of each word – and less strongly on frequency. We develop a generative model of this behavior that fully determines the dynamics of word usage. Conclusions/Significance: Recurrence patterns of words are well described by a stretched exponential distribution of recurrence times, an empirical scaling that cannot be anticipated from Zipf’s law. Because the use of words provides a uniquely precise and powerful lens on human thought and activity, our findings also have implications for other overt manifestations of collective human dynamics.
💡 Research Summary
The paper investigates the temporal dynamics of word usage by analyzing the intervals between successive occurrences of the same word—so‑called recurrence times—in large text corpora. While Zipf’s law famously describes the static distribution of word frequencies as a power‑law, it says nothing about how words are spaced in time. To fill this gap, the authors examine high‑frequency words in USENET discussion groups and in three additional corpora that differ in formality (news articles, Wikipedia entries, and novels). For each word they extract the series of inter‑occurrence distances τ and compute the empirical probability density function. The results deviate dramatically from the exponential distribution expected for a Poisson (memoryless) process. Instead, the data are well fitted by a stretched‑exponential, or Weibull, distribution
P(τ)= (β/τ₀)(τ/τ₀)^{β‑1} exp
Comments & Academic Discussion
Loading comments...
Leave a Comment