Main-path analysis and path-dependent transitions in HistCite(TM)-based historiograms
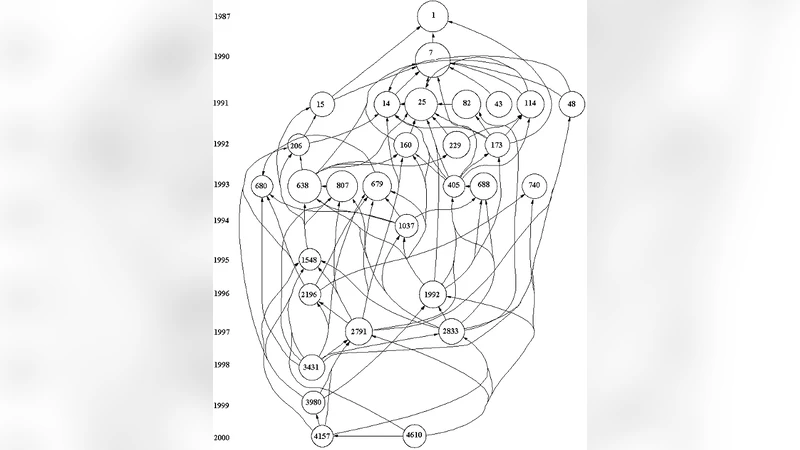
With the program HistCite(TM) it is possible to generate and visualize the most relevant papers in a set of documents retrieved from the Science Citation Index. Historical reconstructions of scientific developments can be represented chronologically as developments in networks of citation relations extracted from scientific literature. This study aims to go beyond the historical reconstruction of scientific knowledge, enriching the output of HistCite(TM) with algorithms from social network analysis and information theory.
💡 Research Summary
The paper expands the capabilities of HistCite™—a tool that extracts citation networks from the Science Citation Index and visualizes them as historiograms—by integrating methods from social network analysis and information theory. While HistCite™ provides basic bibliometric indicators such as total citations, local and global citation scores, and chronological histograms of influential papers, it does not reveal the dynamic pathways through which scientific knowledge evolves or the moments when a field undergoes a paradigm shift. To address these gaps, the authors introduce two complementary analytical frameworks: main‑path analysis and path‑dependent transition detection.
Main‑path analysis identifies the most influential citation routes within a network by applying the Search Path Link Count (SPLC) and Search Path Node Pair (SPNP) algorithms. These techniques assign weights to citation links and node pairs based on frequency, temporal proximity, and directionality, allowing the extraction of a “main path” that captures the highest flow of knowledge rather than merely the most cited papers. This provides a structural backbone of a research field, highlighting which publications have truly guided subsequent work.
Path‑dependent transition detection leverages entropy and mutual information from information theory. The citation network is modeled as a probability distribution over time; abrupt changes in entropy signal structural re‑organization of the network, interpreted as transition points where new paradigms emerge or existing ones are replaced. By comparing main paths before and after these transition points, the authors assess the degree of path dependence—whether early seminal works constrain or enable later developments.
The methodology is demonstrated on two distinct corpora. The first corpus comprises 500+ papers in Science and Technology Studies (1970‑2000). Analysis shows that a 1975 “innovation diffusion” article anchors the early main path, while a sharp entropy increase around 1995 coincides with the rise of “knowledge‑based economy” literature, marking a transition that reshapes the main path away from the original diffusion model. The second corpus includes 500+ molecular biology papers (1990‑2010). Here, a 1992 “DNA replication mechanism” paper dominates the early network, but a 2003 surge in “RNA interference (RNAi)” publications triggers a pronounced entropy spike, indicating a transition that reconfigures the main path toward RNAi‑centric research.
These case studies illustrate that (1) main‑path analysis uncovers the structural spine of scientific development beyond simple citation counts, and (2) entropy‑based transition detection pinpoints moments of paradigm change, confirming the presence of path dependence in knowledge evolution. The combined approach offers policymakers and research managers a more nuanced view of innovation dynamics, enabling early detection of emerging fields and more informed allocation of resources.
The authors acknowledge limitations such as incomplete citation data, database coverage biases, and sensitivity of algorithmic parameters. They suggest future work integrating multiple citation sources (e.g., Scopus, Google Scholar), employing time‑weighted citation models, and applying machine‑learning techniques to predict future main paths. Such enhancements could yield a more robust, predictive model of scientific knowledge flows.
Comments & Academic Discussion
Loading comments...
Leave a Comment