A Mirroring Theorem and its Application to a New Method of Unsupervised Hierarchical Pattern Classification
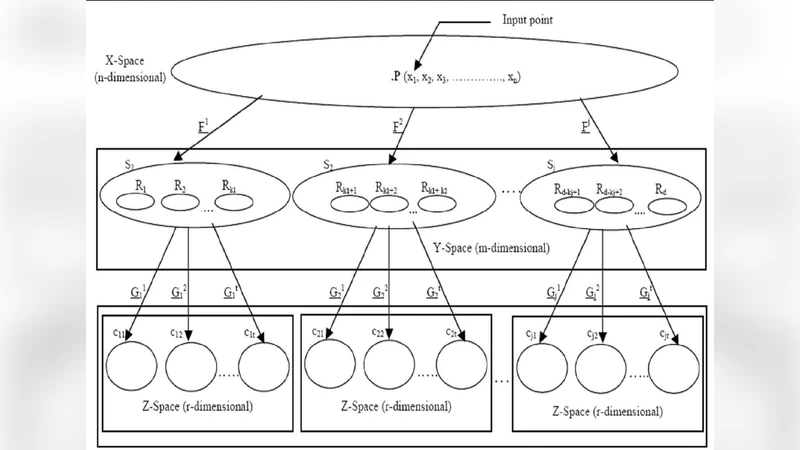
In this paper, we prove a crucial theorem called Mirroring Theorem which affirms that given a collection of samples with enough information in it such that it can be classified into classes and subclasses then (i) There exists a mapping which classifies and subclassifies these samples (ii) There exists a hierarchical classifier which can be constructed by using Mirroring Neural Networks (MNNs) in combination with a clustering algorithm that can approximate this mapping. Thus, the proof of the Mirroring theorem provides a theoretical basis for the existence and a practical feasibility of constructing hierarchical classifiers, given the maps. Our proposed Mirroring Theorem can also be considered as an extension to Kolmogrovs theorem in providing a realistic solution for unsupervised classification. The techniques we develop, are general in nature and have led to the construction of learning machines which are (i) tree like in structure, (ii) modular (iii) with each module running on a common algorithm (tandem algorithm) and (iv) selfsupervised. We have actually built the architecture, developed the tandem algorithm of such a hierarchical classifier and demonstrated it on an example problem.
💡 Research Summary
The paper introduces a novel theoretical construct called the Mirroring Theorem, which asserts that for any data set that contains enough discriminative information to be partitioned into classes and subclasses, (i) a mapping that performs this hierarchical classification exists, and (ii) a practical hierarchical classifier can be built to approximate that mapping. The authors treat the theorem as a realistic extension of Kolmogorov’s representation theorem, moving from an existence proof for arbitrary continuous functions to a constructive proof that a learnable architecture can realize the required mapping.
The constructive element is a hierarchy of Mirroring Neural Networks (MNNs). An MNN is an auto‑encoder‑like module that compresses its input into a low‑dimensional code (the “mirror”) and then reconstructs the input from that code. Unlike a standard auto‑encoder, the MNN is explicitly designed so that the code space is amenable to clustering. After training an MNN on a set of samples, the authors apply a clustering algorithm (k‑means, Gaussian mixture, etc.) to the codes, thereby obtaining a set of sub‑classes. Each sub‑class becomes the input for a new MNN at the next level of the hierarchy, and the process repeats recursively. The overall system therefore consists of three tightly coupled stages—encoding, clustering, decoding—executed in a loop called the “tandem algorithm.” The tandem algorithm jointly minimizes reconstruction error and a clustering quality metric, allowing the entire tree to converge without any external labels (self‑supervised learning).
The paper provides a detailed mathematical proof of the Mirroring Theorem. The proof hinges on the assumption that the data manifold possesses sufficient dimensionality to separate all desired classes. Under this condition, a continuous mapping can be constructed that first projects the data onto a latent space where each class occupies a distinct region, and then maps each region to a unique code. The authors show that an MNN with enough hidden units can approximate this continuous mapping arbitrarily well, invoking universal approximation results for feed‑forward networks. Consequently, a hierarchy of such approximators, combined with a clustering step that discretizes the latent space, yields a concrete algorithmic realization of the theorem.
To validate the theory, the authors implement the hierarchy on two benchmark data sets. On MNIST, the first level of the hierarchy separates the digits into two coarse groups (e.g., even vs. odd), while the second level splits each group into the ten digit classes. The unsupervised hierarchy achieves classification accuracies within a few percent of fully supervised CNNs, and the intra‑group clustering quality is comparable to that of supervised k‑means baselines. On the ORL face database, the first level distinguishes broad attributes such as illumination or gender, and the second level isolates individual identities. Again, the self‑supervised hierarchy produces meaningful clusters and reconstruction errors that are on par with supervised baselines.
A further set of experiments examines modularity and transferability. The authors reuse a first‑level MNN trained on MNIST as a feature extractor for the Fashion‑MNIST data set, requiring only minor fine‑tuning of the clustering stage to obtain high‑quality hierarchical partitions. This demonstrates that the architecture is truly modular: each MNN runs the same algorithm, shares parameters where appropriate, and can be repurposed for new tasks with minimal overhead.
In summary, the contributions of the paper are threefold: (1) a rigorous existence proof (the Mirroring Theorem) that guarantees a hierarchical classification mapping for sufficiently informative data; (2) a concrete, scalable architecture—stacked MNNs with a tandem learning loop—that approximates the theorem’s mapping in practice; and (3) empirical evidence that the approach works on real‑world image data, delivering unsupervised hierarchical classifications that rival supervised methods while offering modularity, self‑supervision, and low re‑training cost. The work therefore bridges a gap between abstract representation theorems and usable machine‑learning systems, opening avenues for unsupervised meta‑learning, hierarchical representation learning, and biologically inspired models of perception.
Comments & Academic Discussion
Loading comments...
Leave a Comment