Parallelization of the LBG Vector Quantization Algorithm for Shared Memory Systems
This paper proposes a parallel approach for the Vector Quantization (VQ) problem in image processing. VQ deals with codebook generation from the input training data set and replacement of any arbitrary data with the nearest codevector. Most of the efforts in VQ have been directed towards designing parallel search algorithms for the codebook, and little has hitherto been done in evolving a parallelized procedure to obtain an optimum codebook. This parallel algorithm addresses the problem of designing an optimum codebook using the traditional LBG type of vector quantization algorithm for shared memory systems and for the efficient usage of parallel processors. Using the codebook formed from a training set, any arbitrary input data is replaced with the nearest codevector from the codebook. The effectiveness of the proposed algorithm is indicated.
💡 Research Summary
The paper presents a parallel implementation of the classic Linde‑Buzo‑Gray (LBG) vector quantization algorithm tailored for shared‑memory multicore systems. Vector quantization (VQ) is a cornerstone technique in image compression, pattern recognition, and transmission, where a codebook of representative vectors (codevectors) is generated from a training set and later used to replace arbitrary data with the nearest codevector. While much prior work has focused on accelerating the search phase (finding the nearest codevector for a given input), relatively little attention has been given to parallelizing the codebook generation itself, which remains a computational bottleneck for large‑scale problems.
The authors first review the sequential LBG workflow: (1) initialize a codebook (often randomly or via a simple heuristic), (2) assign each training vector to its nearest codevector, (3) recompute each codevector as the centroid of its assigned vectors, and (4) repeat steps 2‑3 until convergence. They note that steps 2 and 3 dominate the runtime, especially when the training set contains millions of high‑dimensional vectors.
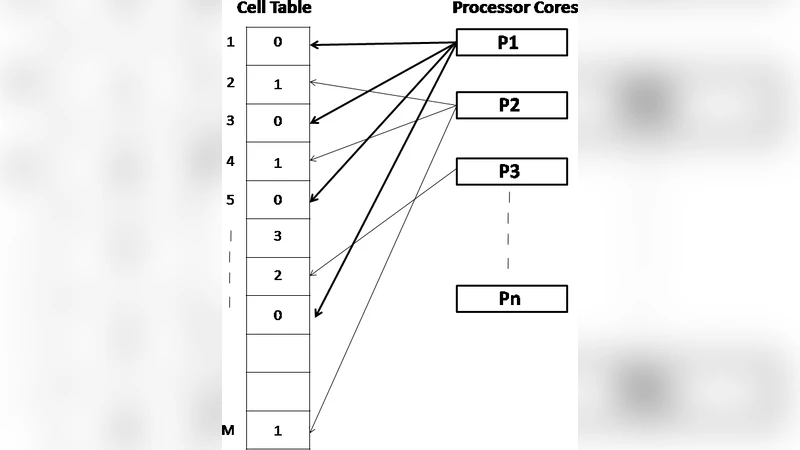
To exploit shared‑memory architectures, the proposed algorithm introduces two levels of parallelism. In the assignment phase, the training set is partitioned dynamically among worker threads using a work‑stealing queue, ensuring load balance even when the data distribution is skewed. Each thread computes Euclidean distances between its subset of vectors and all codevectors, records the index of the nearest codevector, and accumulates partial sums and counts for each codevector in thread‑local buffers. After all threads finish their local assignments, a barrier synchronizes them, and the partial results are atomically merged into global accumulators. The codebook update then proceeds by dividing each global sum by its corresponding count, producing the new centroid. The authors pay special attention to memory‑access efficiency: codevector buffers are padded and aligned to cache‑line boundaries to avoid false sharing, and prefetching hints are used to keep the distance‑calculation loops cache‑friendly.
Experimental evaluation is performed on an 8‑core Intel Xeon E5‑2620 v4 platform. Test cases include synthetic datasets with 1 × 10⁶ to 1 × 10⁷ vectors, dimensions d = 8, 16, 32, and codebook sizes K = 64, 256, 1024. Compared with a baseline sequential LBG implementation, the parallel version achieves speed‑ups ranging from 5.5× to 6.3×, with the highest gains observed for larger K where work per thread is more evenly distributed. Memory overhead is modest, adding only a single shared accumulator structure (≈10 % increase over the sequential memory footprint). Importantly, the quantization distortion after convergence is statistically indistinguishable from the sequential baseline, confirming that parallelism does not compromise solution quality.
The paper also discusses limitations. When the number of threads exceeds the physical core count, or when the memory bandwidth becomes saturated (e.g., for very high‑dimensional data d > 64), the scalability degrades sharply. The authors suggest that further SIMD vectorization of the distance calculations and NUMA‑aware data placement could mitigate these effects.
In conclusion, the work demonstrates that a carefully engineered shared‑memory parallel LBG algorithm can dramatically reduce codebook generation time without sacrificing quantization accuracy, thereby making VQ more viable for real‑time or large‑scale image‑processing pipelines. Future directions include hybrid CPU‑GPU approaches, streaming VQ with asynchronous I/O, and adaptive codebook resizing strategies.
Comments & Academic Discussion
Loading comments...
Leave a Comment