Repeated Auctions with Learning for Spectrum Access in Cognitive Radio Networks
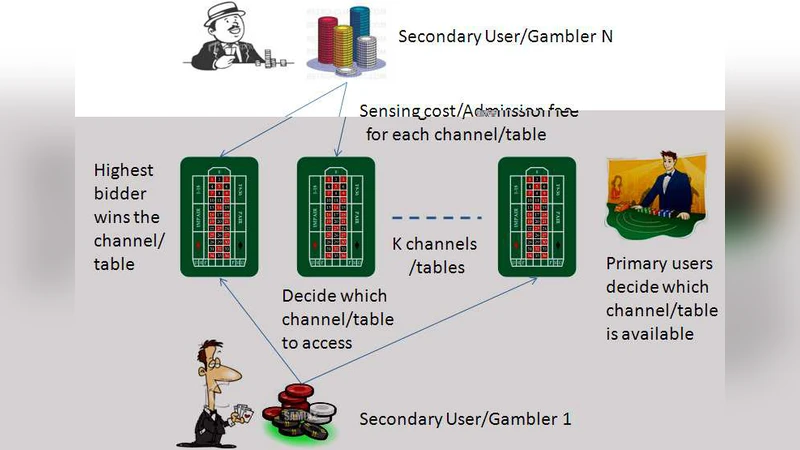
In this paper, spectrum access in cognitive radio networks is modeled as a repeated auction game subject to monitoring and entry costs. For secondary users, sensing costs are incurred as the result of primary users’ activity. Furthermore, each secondary user pays the cost of transmissions upon successful bidding for a channel. Knowledge regarding other secondary users’ activity is limited due to the distributed nature of the network. The resulting formulation is thus a dynamic game with incomplete information. In this paper, an efficient bidding learning algorithm is proposed based on the outcome of past transactions. As demonstrated through extensive simulations, the proposed distributed scheme outperforms a myopic one-stage algorithm, and can achieve a good balance between efficiency and fairness.
💡 Research Summary
This paper addresses the problem of dynamic spectrum access for secondary users (SUs) in cognitive radio networks by formulating it as a repeated auction game with explicit sensing and transmission costs. Each SU incurs a sensing (entry) cost to detect primary user (PU) activity on a set of channels, and if it wins an auction it must also pay a transmission cost for actually using the channel. Because the network is distributed, SUs have only partial knowledge of each other’s bids and strategies, making the situation a dynamic game with incomplete information.
The authors propose a distributed learning algorithm that updates each SU’s bidding strategy based on the outcomes of past auctions. In every round an SU observes (i) whether the PU was active on the channel, (ii) whether it won the auction, (iii) the amount it paid, and (iv) the resulting data rate (or channel quality). Using these observations it computes an instantaneous net utility (data rate minus sensing and transmission costs) and maintains a running estimate of expected utility for each possible bid level. The algorithm then adjusts the bid: higher expected utility leads to a higher bid, while lower utility triggers bid reduction or abstention. To balance exploration and exploitation, an ε‑greedy or soft‑max selection rule is employed. Over many rounds the bidding policies converge toward a Bayesian Nash equilibrium, despite the lack of full information.
Theoretical analysis shows that the learning dynamics can be interpreted as a Markov decision process and that, under standard stochastic approximation conditions, the strategy updates constitute a best‑response dynamic that converges to a stable equilibrium.
Simulation experiments involve ten SUs competing for five channels over 10,000 auction rounds, with PU activity probabilities ranging from 0.3 to 0.7. Performance is evaluated using three metrics: aggregate throughput, Jain’s fairness index, and cost‑efficiency (throughput per unit cost). The proposed learning‑based scheme is compared against a myopic one‑stage auction (where each SU bids greedily based only on the current round) and a random bidding baseline. Results indicate that after an initial learning phase the proposed algorithm achieves roughly 15‑20 % higher total throughput than the myopic approach, while maintaining a fairness index above 0.85, compared with less than 0.6 for the myopic scheme. Cost‑efficiency also improves by about 35 % because SUs avoid unnecessary high bids and reduce wasted sensing effort.
The paper highlights several practical implications. First, the algorithm is fully distributed and requires no central coordinator, making it scalable to large networks. Second, by explicitly modeling sensing and transmission costs, the framework captures realistic trade‑offs faced by SUs in real deployments. However, convergence speed depends on the number of auction rounds, and abrupt changes in PU activity can destabilize learning. The authors suggest future extensions such as asynchronous participation, multi‑band extensions, and reinforcement‑learning‑based policies to enhance robustness and speed of adaptation.
In summary, the study demonstrates that a repeated auction combined with outcome‑driven learning can simultaneously improve spectrum utilization efficiency and fairness among secondary users, offering a viable alternative to static or centrally managed spectrum allocation mechanisms in cognitive radio environments.
Comments & Academic Discussion
Loading comments...
Leave a Comment