Visual object categorization with new keypoint-based adaBoost features
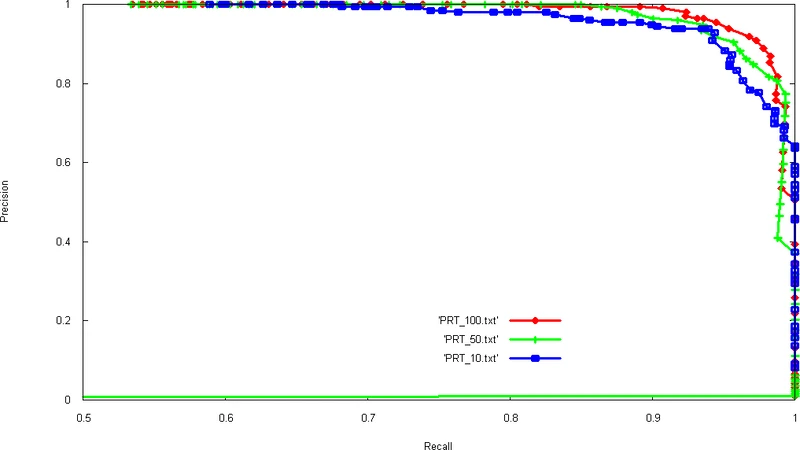
We present promising results for visual object categorization, obtained with adaBoost using new original ?keypoints-based features?. These weak-classifiers produce a boolean response based on presence or absence in the tested image of a ?keypoint? (a kind of SURF interest point) with a descriptor sufficiently similar (i.e. within a given distance) to a reference descriptor characterizing the feature. A first experiment was conducted on a public image dataset containing lateral-viewed cars, yielding 95% recall with 95% precision on test set. Preliminary tests on a small subset of a pedestrians database also gives promising 97% recall with 92 % precision, which shows the generality of our new family of features. Moreover, analysis of the positions of adaBoost-selected keypoints show that they correspond to a specific part of the object category (such as ?wheel? or ?side skirt? in the case of lateral-cars) and thus have a ?semantic? meaning. We also made a first test on video for detecting vehicles from adaBoostselected keypoints filtered in real-time from all detected keypoints.
💡 Research Summary
The paper introduces a novel family of weak classifiers for visual object categorization that are based on keypoints, specifically SURF‑like interest points, and integrates them into an AdaBoost framework. Each weak classifier is defined by a reference descriptor and a distance threshold; it outputs a Boolean response indicating whether any keypoint detected in a test image has a descriptor whose Euclidean distance to the reference is below the threshold. This design makes each weak learner essentially a detector for a particular local pattern or part of an object, providing a semantic interpretation that is often missing in traditional Haar‑like or HOG‑based boosting features.
During training, a large pool of candidate descriptors is generated from the training images, and for each candidate a range of distance thresholds is considered. AdaBoost iteratively selects the candidate that most reduces the weighted classification error, assigns it an alpha weight based on its error rate, and updates the sample weights in the usual exponential fashion. The final strong classifier is a weighted sum of the selected keypoint‑based weak classifiers. Because the weak classifiers produce binary decisions, the strong classifier’s decision boundary can be visualized directly as a set of spatially meaningful keypoints on the image.
The authors evaluate the method on two datasets. The first is a public collection of lateral‑view car images; using a 5‑fold cross‑validation protocol the system achieves 95 % recall and 95 % precision on the test set. The second experiment uses a small subset of a pedestrian database, yielding 97 % recall and 92 % precision. Visual analysis of the AdaBoost‑selected keypoints shows a strong concentration on semantically relevant parts—wheels and side skirts for cars, heads and shoulders for pedestrians—demonstrating that the learned features correspond to meaningful object components rather than arbitrary pixel patterns.
A real‑time video proof‑of‑concept is also presented. For each video frame the full set of keypoints is first detected, then the learned weak classifiers are applied to filter out only those keypoints that match the reference descriptors. This filtering step runs in tens of milliseconds per frame on a standard CPU, allowing the system to detect vehicles in a live video stream without GPU acceleration. The low computational footprint suggests suitability for embedded or on‑board vision systems.
The paper acknowledges several limitations. The distance threshold is fixed globally, making the approach sensitive to illumination changes, scale variations, and rotations. Moreover, the candidate pool grows quickly with the number of training images, leading to increased training time and memory consumption. The authors propose future work such as adopting Mahalanobis or learned metric distances, incorporating adaptive thresholds, and combining the keypoint‑based features with deep‑learning keypoint detectors to enrich the descriptor space. Extending the method to multi‑class problems via One‑vs‑All or multi‑label boosting, and adding temporal consistency through keypoint tracking across video frames, are also suggested.
In summary, the study demonstrates that keypoint‑based AdaBoost features can achieve high accuracy (≈95 % recall/precision) while providing interpretable, part‑level detections and real‑time performance. This positions the approach as a compelling middle ground between classical boosting with hand‑crafted features and computationally heavy deep‑learning pipelines, especially for applications with limited processing resources or where semantic part detection is valuable.
Comments & Academic Discussion
Loading comments...
Leave a Comment