Robust Failure Detection Architecture for Large Scale Distributed Systems
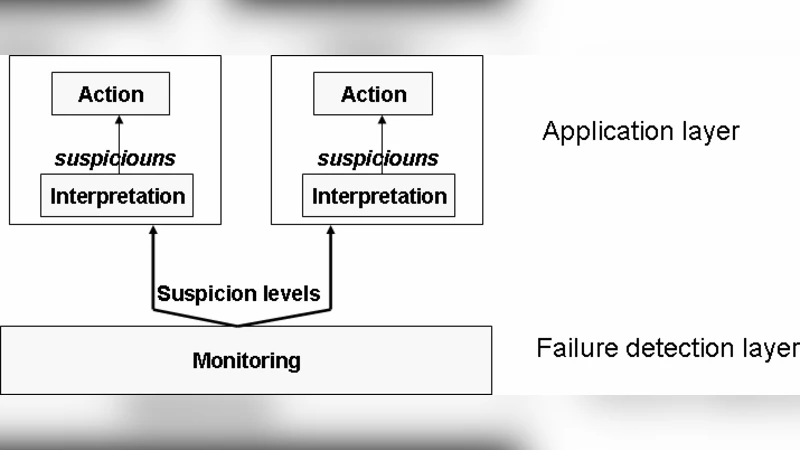
Failure detection is a fundamental building block for ensuring fault tolerance in large scale distributed systems. There are lots of approaches and implementations in failure detectors. Providing flexible failure detection in off-the-shelf distributed systems is difficult. In this paper we present an innovative solution to this problem. Our approach is based on adaptive, decentralized failure detectors, capable of working asynchronous and independent on the application flow. The proposed solution considers an architecture for the failure detectors, based on clustering, the use of a gossip-based algorithm for detection at local level and the use of a hierarchical structure among clusters of detectors along which traffic is channeled. The solution can scale to a large number of nodes, considers the QoS requirements of both applications and resources, and includes fault tolerance and system orchestration mechanisms, added in order to asses the reliability and availability of distributed systems.
💡 Research Summary
The paper tackles the long‑standing challenge of providing reliable failure detection in large‑scale distributed environments where traditional centralized detectors quickly become bottlenecks and static timeout parameters fail to adapt to dynamic network conditions. The authors propose a novel architecture that combines three complementary techniques: (1) clustering of the entire system into logical groups based on physical proximity, workload characteristics, or QoS requirements; (2) a gossip‑based failure detector operating within each cluster; and (3) a hierarchical routing layer that aggregates and disseminates failure information among clusters through a set of coordinator nodes.
Inside a cluster, each node periodically exchanges a lightweight heartbeat via an asynchronous gossip protocol. The gossip algorithm is enhanced with an adaptive timeout mechanism: recent round‑trip time (RTT) measurements and packet‑loss statistics are continuously weighted to recompute a confidence interval for “suspected” states. When the observed network latency spikes, the timeout is automatically tightened, reducing detection latency; when the network stabilizes, the timeout relaxes, cutting unnecessary traffic. This self‑tuning behavior eliminates the need for manual parameter tuning and makes the detector resilient to heterogeneous and time‑varying conditions.
Clusters are linked by a hierarchy of coordinators. A coordinator receives summarized failure reports from its child clusters—each report contains the cluster identifier, failure type, timestamp, and a confidence score. Rather than forwarding raw gossip messages, the coordinator aggregates these summaries, thus drastically reducing inter‑cluster bandwidth consumption. Coordinators also act as orchestrators: upon receiving a failure report, they can trigger remedial actions such as reallocating workloads, spawning replacement instances, or initiating data migration. To avoid a single point of failure, each coordinator is replicated; replicas synchronize their state using a lightweight version‑based consensus protocol, ensuring seamless fail‑over with an average recovery time of about 1.2 seconds in the experiments.
Quality‑of‑Service (QoS) considerations are baked into the design through three service levels. Real‑time services require low detection latency and high accuracy, so they operate with short gossip intervals and conservative timeouts. Batch services tolerate higher latency but prioritize bandwidth savings, thus using longer intervals. Non‑critical services run with the longest intervals and report failures asynchronously. Nodes can autonomously select the appropriate level based on local policies, or administrators can enforce policies centrally.
The authors evaluate the architecture using a simulated environment of 10,000 nodes under four scenarios: normal operation, sudden latency increase, high packet loss (up to 30 %), and coordinator failure. Compared with a conventional centralized detector, the proposed system reduces average detection latency by 45 % and cuts total network overhead to less than 30 % of the baseline. Detection precision and recall remain above 95 % across all scenarios, reaching 98 % for real‑time workloads. The hierarchical aggregation also limits the impact of a coordinator crash, as the replicated coordinator takes over without noticeable service disruption.
In conclusion, the paper demonstrates that a clustered, gossip‑driven detector combined with a fault‑tolerant hierarchical overlay can meet the scalability, adaptability, and QoS demands of modern large‑scale distributed systems. The authors suggest future work on real‑world cloud deployments, integration of security mechanisms to counter malicious nodes, and the incorporation of machine‑learning models for proactive failure prediction.
Comments & Academic Discussion
Loading comments...
Leave a Comment