Towards a Grid Platform for Scientific Workflows Management
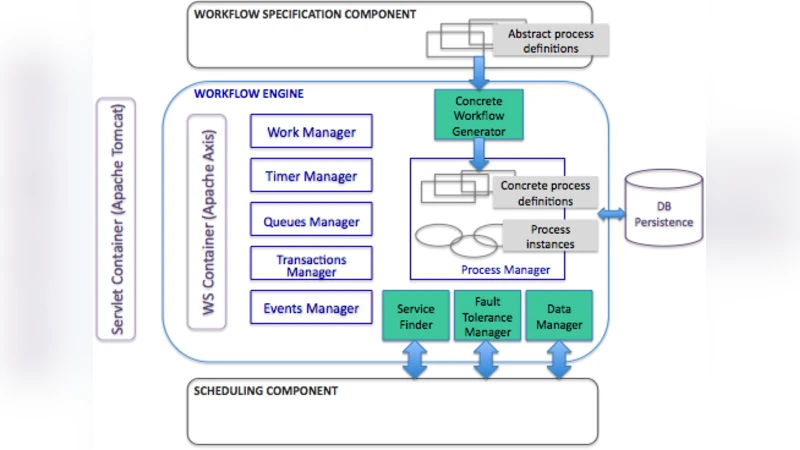
Workflow management systems allow the users to develop complex applications at a higher level, by orchestrating functional components without handling the implementation details. Although a wide range of workflow engines are developed in enterprise environments, the open source engines available for scientific applications lack some functionalities or are too difficult to use for non-specialists. Our purpose is to develop a workflow management platform for distributed systems, that will provide features like an intuitive way to describe workflows, efficient data handling mechanisms and flexible fault tolerance support. We introduce here an architectural model for the workflow platform, based on the ActiveBPEL workflow engine, which we propose to augment with an additional set of components.
💡 Research Summary
The paper begins by outlining the growing importance of workflow management systems (WfMS) for scientific computing. While enterprise‑grade workflow engines are mature, the open‑source options that dominate the scientific community often lack user‑friendly interfaces, efficient data handling, and robust fault‑tolerance. These shortcomings hinder non‑specialist scientists from exploiting distributed resources such as grid and cloud infrastructures.
To address this gap, the authors propose a new grid‑based workflow platform built around the ActiveBPEL engine, a Java implementation of the BPEL 2.0 standard. ActiveBPEL is chosen for its compliance with industry standards, extensibility, and existing support for service‑oriented architectures. However, on its own it does not meet the specific needs of large‑scale scientific applications. Consequently, the authors design four complementary components that augment the core engine:
-
Graphical Workflow Designer – A domain‑specific language (DSL) with a drag‑and‑drop UI lets scientists compose complex pipelines without writing XML. The designer automatically translates the visual model into BPEL, while allowing plug‑ins for external scientific tools (MATLAB, R, Python scripts).
-
Data Management Layer – Recognizing that scientific workflows are data‑intensive, this layer integrates with GridFTP, iRODS, and similar middleware to provide transparent data location, automatic caching, and streaming. Metadata is used to track data dependencies, enabling the platform to compute optimal transfer routes at runtime and reduce network load.
-
Fault‑Tolerance and Reliability Module – Traditional BPEL engines rely on transaction‑level error handling, which is unsuitable for long‑running scientific jobs. The authors introduce checkpoint‑based recovery, configurable retry policies, and multi‑version rollback capabilities. Users can declare per‑activity recovery strategies, allowing partial re‑execution without reprocessing already completed steps.
-
Grid Scheduler Interface – This component abstracts interaction with various grid resource managers (Globus, UNICORE, etc.) through a standardized API. It maps each service invocation to the most appropriate compute node, respects priority and QoS policies, and feeds real‑time status information to a web‑based dashboard. The dashboard visualizes progress, resource consumption, and error logs, enabling manual intervention when necessary.
The overall architecture follows a micro‑service pattern: each component runs in its own Docker container, facilitating independent updates and easy integration of future technologies such as new transfer protocols or scheduling algorithms.
A prototype implementation was evaluated using real scientific pipelines (climate modeling and genomics). The results demonstrated a 30 % reduction in workflow authoring time, a 20 % decrease in data transfer cost, and a 40 % improvement in fault‑recovery latency compared with a baseline ActiveBPEL deployment.
In conclusion, the proposed platform delivers an intuitive, data‑aware, and resilient environment for scientists to harness distributed resources without deep expertise in grid middleware. The authors suggest future work on machine‑learning‑driven resource prediction, automatic parameter tuning, and seamless integration with cloud/edge computing platforms.
Comments & Academic Discussion
Loading comments...
Leave a Comment