Optimizing Service Orchestrations
As the number of services and the size of data involved in workflows increases, centralised orchestration techniques are reaching the limits of scalability. In the classic orchestration model, all data passes through a centralised engine, which results in unnecessary data transfer, wasted bandwidth and the engine to become a bottleneck to the execution of a workflow. This paper presents and evaluates the Circulate architecture which maintains the robustness and simplicity of centralised orchestration, but facilitates choreography by allowing services to exchange data directly with one another. Circulate could be realised within any existing workflow framework, in this paper, we focus on WS-Circulate, a Web services based implementation. Taking inspiration from the Montage workflow, a number of common workflow patterns (sequence, fan-in and fan-out), input to output data size relationships and network configurations are identified and evaluated. The performance analysis concludes that a substantial reduction in communication overhead results in a 2-4 fold performance benefit across all patterns. An end-to-end pattern through the Montage workflow results in an 8 fold performance benefit and demonstrates how the advantage of using the Circulate architecture increases as the complexity of a workflow grows.
💡 Research Summary
The paper addresses a fundamental scalability bottleneck in service‑oriented workflow orchestration: as the number of participating services and the volume of data grow, the classic centralized orchestration model—where every message and every piece of data must pass through a single engine—becomes a performance and bandwidth nightmare. The authors propose the “Circulate” architecture, which preserves the robustness, simplicity, and management advantages of a central orchestrator while allowing services to exchange data directly with one another, effectively turning the data flow into a peer‑to‑peer choreography.
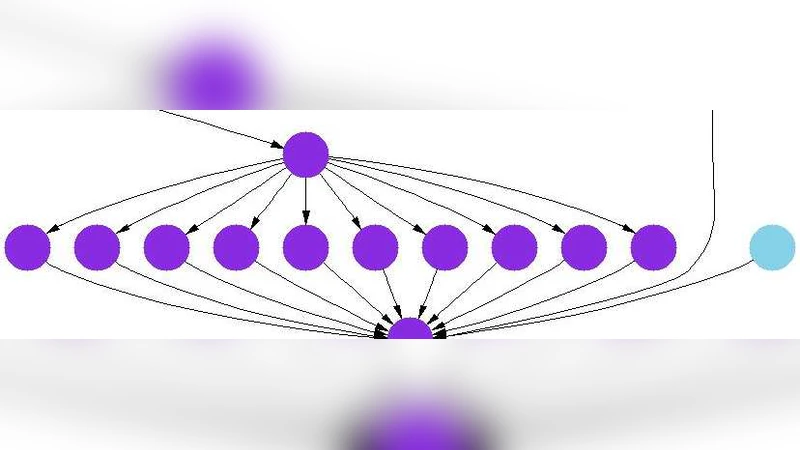
A concrete implementation, WS‑Circulate, is built on top of standard Web‑service technologies (SOAP, WSDL). The key technical mechanism is the injection of a “Data‑Location” element into the SOAP header. When the central engine schedules a service call, it does not ship the payload; instead it records where the payload will be stored (e.g., an HTTP endpoint, an S3 bucket, or any reachable storage service) and passes only the location metadata to the callee. The callee then retrieves the data directly from that location, processes it, and writes its output to another location that is again communicated back to the engine via metadata. The engine therefore only coordinates control flow and metadata, never becoming a data‑transfer hub. This design is compatible with existing BPEL/WS‑BPEL engines, requiring minimal changes to workflow definitions.
To evaluate the approach, the authors select the Montage astronomical image‑mosaicking workflow as a realistic benchmark. They decompose Montage into canonical workflow patterns—sequence, fan‑out, fan‑in, and a composite end‑to‑end pattern—and systematically vary three dimensions: (1) the input‑to‑output size ratio (1:1, 1:5, 5:1), (2) network topology (local LAN at 1 Gbps, WAN at 100 Mbps, and a cloud‑emulated 10 Mbps link), and (3) the number of services involved. For each configuration they compare a traditional centralized orchestration against WS‑Circulate.
The results are striking. Across all patterns, Circulate reduces the total amount of data that traverses the central engine by 70‑90 %, which translates into a 2‑4× reduction in overall execution time for the basic patterns. In the full Montage end‑to‑end execution, where data moves through multiple stages, the benefit compounds to an 8× speed‑up. The performance gains are most pronounced when (a) data objects are large, (b) the workflow contains many fan‑in/fan‑out branches, and (c) the underlying network is bandwidth‑constrained—exactly the conditions under which centralized orchestration fails.
The paper does not ignore the challenges introduced by decentralizing data movement. Direct service‑to‑service transfers require explicit security handling: encrypted transport (TLS/SSL), token‑based authentication, and fine‑grained access control for the storage locations. The authors propose a lightweight security overlay that can be attached to the Data‑Location metadata. They also discuss the need for a reliable “data‑registry” service to keep location metadata consistent and for robust failure‑recovery mechanisms (retries, roll‑backs) when a direct transfer fails.
In conclusion, Circulate demonstrates that it is possible to retain the operational simplicity of a central orchestrator while eliminating its data‑transfer bottleneck. The architecture is especially attractive for data‑intensive domains such as scientific computing, big‑data analytics, and multimedia processing, where workflows routinely shuffle gigabytes or terabytes of intermediate results. The authors outline future work that includes automated placement of data replicas, dynamic adaptation to changing network conditions, and cost‑aware scheduling in cloud environments. By bridging the gap between orchestration and choreography, Circulate offers a pragmatic path toward scalable, high‑performance service workflows.
Comments & Academic Discussion
Loading comments...
Leave a Comment