Watermarking Digital Images Based on a Content Based Image Retrieval Technique
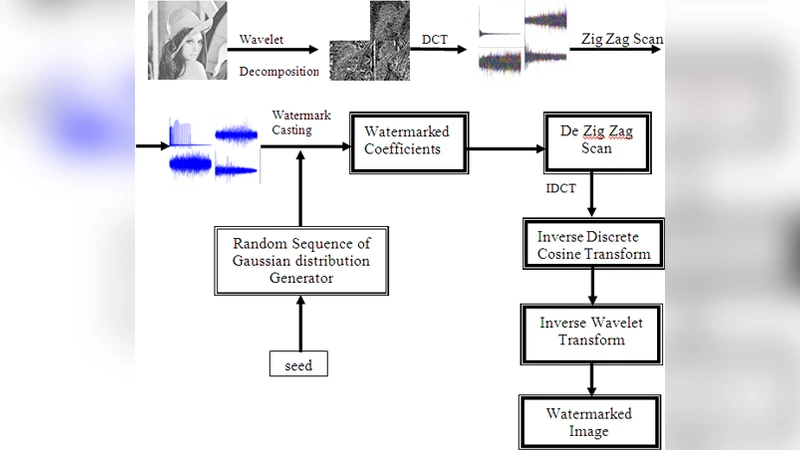
The current work is focusing on the implementation of a robust watermarking algorithm for digital images, which is based on an innovative spread spectrum analysis algorithm for watermark embedding and on a content-based image retrieval technique for watermark detection. The highly robust watermark algorithms are applying “detectable watermarks” for which a detection mechanism checks if the watermark exists or no (a Boolean decision) based on a watermarking key. The problem is that the detection of a watermark in a digital image library containing thousands of images means that the watermark detection algorithm is necessary to apply all the keys to the digital images. This application is non-efficient for very large image databases. On the other hand “readable” watermarks may prove weaker but easier to detect as only the detection mechanism is required. The proposed watermarking algorithm combine’s the advantages of both “detectable” and “readable” watermarks. The result is a fast and robust watermarking algorithm.
💡 Research Summary
The paper presents a novel digital‑image watermarking scheme that seeks to combine the robustness of “detectable” (single‑bit) watermarks with the ease of detection of “readable” (multi‑bit) watermarks. The core of the embedding process is a spread‑spectrum, multibit watermark constructed from several zero‑bit watermarks. Each zero‑bit watermark is a pseudo‑random Gaussian sequence generated with a unique seed. To avoid strong correlation between the sequences (which would increase false‑positive rates), the starting point for each sequence is shifted by one coefficient, effectively desynchronising the casts. The watermark key is a positive integer that serves both as the seed for the first Gaussian sequence and as the source for a vector of fifteen additional seeds, one for each subsequent zero‑bit watermark.
The watermark payload is limited to 16 bits. Bit 0 signals the presence of a watermark; if it is zero the detector stops immediately, saving processing time. Bit 1 is a flag indicating whether the remaining 14‑bit payload has been bit‑reversed. The remaining 14 bits encode the actual message, allowing for 2¹⁴ (= 16384) distinct identifiers. The bit‑reversal trick reduces the number of zero‑bit watermarks that must actually be embedded: if the original binary payload contains more ones than zeros, the payload is inverted, the flag is set, and only the positions of the original zeros (now ones) are cast. Consequently, in the worst case only eight zero‑bit watermarks are inserted, limiting visual distortion while preserving a 16‑bit address space.
A distinctive contribution of the work is the integration of a Content‑Based Image Retrieval (CBIR) system—specifically the QBIC (Query By Image Content) algorithm—into the detection phase. In large image repositories, a blind detector would have to try every possible key, which is computationally infeasible. Instead, the detector first queries the image database with the suspect image. QBIC evaluates similarity based on colour distribution, texture, shape, and other visual features, returning a ranked list of candidate originals together with a similarity score. When the score exceeds a predefined threshold, the detector retrieves the associated “supplementary information” (image ID, seed vector, flag bit, etc.) stored in a relational database. This information provides the exact synchronization parameters needed for the correlation‑based detector to recover the embedded sequences, effectively turning a blind detection problem into a semi‑blind one.
The authors claim that this hybrid approach yields high robustness against common attacks such as JPEG compression, geometric transformations (rotation, scaling, shearing), Gaussian filtering, and additive noise. Because the watermark resides in the mid‑frequency sub‑band of a wavelet‑DCT decomposition, it is less susceptible to compression artefacts while remaining imperceptible; reported PSNR degradation is on the order of 0.5–1 dB. The use of multiple, shifted zero‑bit casts further strengthens resistance to desynchronisation attacks, as the detector can re‑align the image using the retrieved original from the database.
Strengths of the proposed system include:
- Robustness – Spread‑spectrum multibit embedding and desynchronised casting provide resilience comparable to traditional detectable watermarks.
- Efficiency – The CBIR‑driven lookup dramatically reduces the number of keys that must be tested, making the scheme scalable to databases containing thousands of images.
- Low Payload Overhead – A 16‑bit payload is sufficient for unique identification while keeping visual distortion minimal, thanks to the bit‑reversal optimisation.
However, the paper also exhibits several limitations. The reliance on a pre‑populated image database and the QBIC engine introduces significant infrastructure overhead; building and maintaining such a system may be costly for many content owners. The detection performance hinges on the quality of the similarity match; in collections with many visually similar images, false matches could lead to missed detections or false positives. Moreover, the experimental evaluation is only briefly described; quantitative results (e.g., detection rates versus attack strength, processing time benchmarks, comparison with existing blind and non‑blind schemes) are missing, making it difficult to assess the true practical advantage. Finally, the approach is semi‑blind—it still requires access to auxiliary data that may not be available in all deployment scenarios.
Future work could address these gaps by (a) providing a thorough empirical study across diverse attack vectors and database sizes, (b) exploring lightweight CBIR alternatives to reduce system complexity, and (c) investigating ways to embed synchronization cues directly within the watermark to further diminish dependence on external databases. In summary, the paper introduces an inventive combination of spread‑spectrum multibit watermarking and content‑based retrieval that promises both robustness and scalability, but its practical adoption will depend on further validation and engineering of the supporting database infrastructure.
Comments & Academic Discussion
Loading comments...
Leave a Comment