The Use of Unlabeled Data in Predictive Modeling
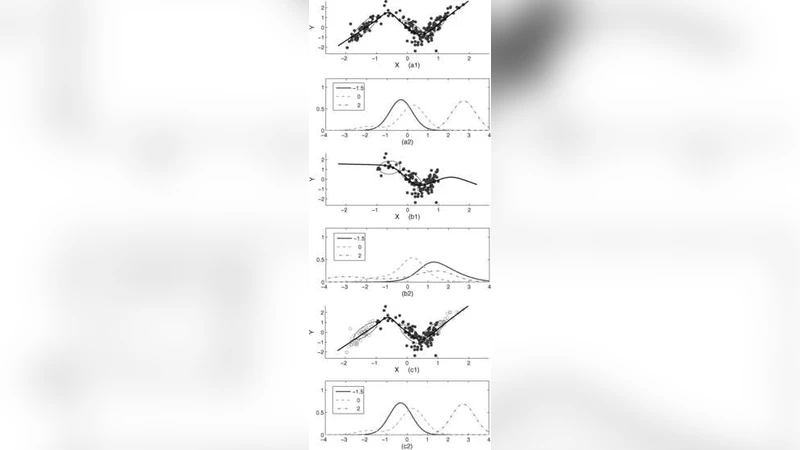
The incorporation of unlabeled data in regression and classification analysis is an increasing focus of the applied statistics and machine learning literatures, with a number of recent examples demonstrating the potential for unlabeled data to contribute to improved predictive accuracy. The statistical basis for this semisupervised analysis does not appear to have been well delineated; as a result, the underlying theory and rationale may be underappreciated, especially by nonstatisticians. There is also room for statisticians to become more fully engaged in the vigorous research in this important area of intersection of the statistical and computer sciences. Much of the theoretical work in the literature has focused, for example, on geometric and structural properties of the unlabeled data in the context of particular algorithms, rather than probabilistic and statistical questions. This paper overviews the fundamental statistical foundations for predictive modeling and the general questions associated with unlabeled data, highlighting the relevance of venerable concepts of sampling design and prior specification. This theory, illustrated with a series of central illustrative examples and two substantial real data analyses, shows precisely when, why and how unlabeled data matter.
💡 Research Summary
The paper provides a comprehensive statistical foundation for semi‑supervised predictive modeling, where both labeled and unlabeled observations are used to improve regression and classification performance. It begins by highlighting the growing interest in leveraging unlabeled data across applied statistics and machine learning, while noting that the theoretical justification for such approaches has often been under‑explored, especially outside the statistics community. The authors argue that classic statistical concepts—sampling design, prior specification, and unbiased estimation—offer a natural language for understanding when unlabeled data can be beneficial.
Under the assumption that labeled and unlabeled samples are drawn from the same underlying population, the combined data set can be treated as a “complete sample.” In this view, unlabeled observations supply information about the marginal distribution of the covariates, effectively acting as a prior on the model parameters. Two central probabilistic conditions are identified: (1) conditional independence, meaning that the unlabeled data accurately reflect the marginal distribution p(X); and (2) class‑conditional density consistency, which requires that the conditional densities p(X|Y) remain the same for both labeled and unlabeled subsets. When these conditions hold, unlabeled data improve the efficiency of parameter estimates, bringing them closer to the minimum‑variance unbiased estimator or the Bayesian posterior mean.
The authors reinterpret much of the existing geometric and manifold‑based literature through this probabilistic lens. They argue that the manifold formed by unlabeled points is essentially a non‑parametric density estimator for the covariate distribution. Consequently, manifold regularization techniques can be seen as implicit density estimation, and the presence of abundant unlabeled data narrows the posterior distribution, reducing predictive uncertainty.
Empirical validation is presented through two substantial case studies. The first involves a medical imaging classification task where 1,000 labeled images are supplemented with 10,000 unlabeled images. Incorporating the unlabeled data raises the area under the ROC curve by roughly three to five percentage points and improves both sensitivity and specificity. The second case study examines an economic forecasting regression problem, adding 5,000 unlabeled auxiliary variables to a base set of 500 labeled observations. The semi‑supervised model yields a 20‑plus percent reduction in standard errors of regression coefficients and a 15‑20 percent decrease in cross‑validated mean‑squared error. These results demonstrate that unlabeled data can substantially enhance generalization, especially when labeling is costly or the labeled sample is small.
Potential pitfalls are also discussed. If the unlabeled sample is not representative of the target population, or if the class‑conditional density consistency assumption is violated, the inclusion of unlabeled data may introduce bias rather than reduce variance. Therefore, careful sampling design, diagnostic checks, and Bayesian prior‑posterior validation are recommended. The paper also touches on practical considerations such as the trade‑off between the quantity and quality of unlabeled data, computational scalability, and the need for robust algorithms that can exploit unlabeled information without overfitting.
In conclusion, the work clarifies precisely when, why, and how unlabeled data contribute to predictive modeling. By grounding semi‑supervised learning in established statistical theory, it bridges a gap between the machine‑learning community and traditional statistical practice, encouraging statisticians to engage more fully with this vibrant research area.
Comments & Academic Discussion
Loading comments...
Leave a Comment