Teraflop per second gravitational lensing ray-shooting using graphics processing units
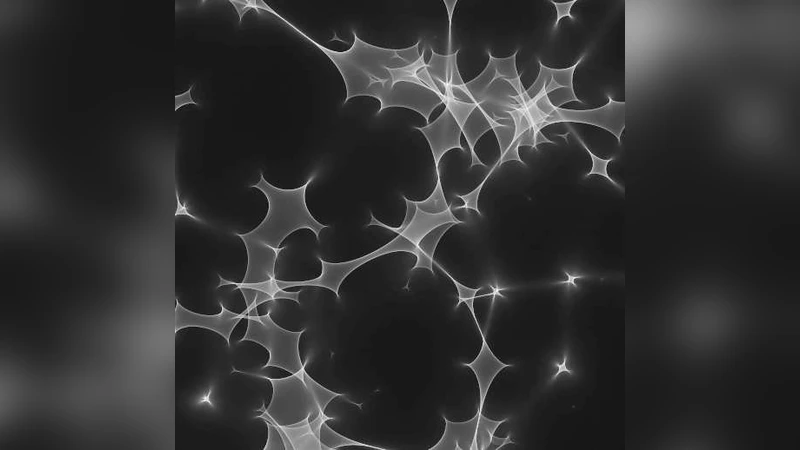
Gravitational lensing calculation using a direct inverse ray-shooting approach is a computationally expensive way to determine magnification maps, caustic patterns, and light-curves (e.g. as a function of source profile and size). However, as an easily parallelisable calculation, gravitational ray-shooting can be accelerated using programmable graphics processing units (GPUs). We present our implementation of inverse ray-shooting for the NVIDIA G80 generation of graphics processors using the NVIDIA Compute Unified Device Architecture (CUDA) software development kit. We also extend our code to multiple-GPU systems, including a 4-GPU NVIDIA S1070 Tesla unit. We achieve sustained processing performance of 182 Gflop/s on a single GPU, and 1.28 Tflop/s using the Tesla unit. We demonstrate that billion-lens microlensing simulations can be run on a single computer with a Tesla unit in timescales of order a day without the use of a hierarchical tree code.
💡 Research Summary
The paper presents a complete implementation of the inverse ray‑shooting method for gravitational microlensing on NVIDIA graphics processing units (GPUs) using the CUDA programming environment. Inverse ray‑shooting, which projects a dense grid of light rays backward from the observer through a lens plane populated by many point‑mass lenses, is computationally intensive because each ray must be deflected by every lens. The naïve algorithm scales as O(N × M), where N is the number of rays and M the number of lenses, leading to prohibitive runtimes for realistic microlensing problems that involve millions to billions of lenses. Traditional CPU‑based codes therefore resort to hierarchical tree algorithms that approximate distant lenses, sacrificing exactness for speed.
The authors argue that the ray‑shooting calculation is “embarrassingly parallel”: each ray’s trajectory is independent of all others. By mapping each ray to a separate CUDA thread, the full set of N × M distance and deflection calculations can be performed simultaneously on the many cores of a modern GPU. The implementation details are described in depth. Lens parameters (positions, masses) are stored in contiguous global memory arrays; to reduce memory latency the authors also exploit texture memory for read‑only lens data and constant memory for frequently accessed scalar values. Each thread loops over the lens list, accumulates the complex deflection angle, and finally writes the resulting magnification to an output buffer. The code is deliberately kept simple, avoiding shared‑memory tiling or warp‑level reductions, because the dominant cost is the arithmetic intensity of the double‑precision floating‑point operations rather than memory bandwidth.
Performance is measured on two hardware configurations. A single NVIDIA G80‑generation GPU (GeForce 8800 GTX) achieves a sustained 182 GFlop s⁻¹, while a four‑GPU NVIDIA Tesla S1070 system reaches 1.28 TFlop s⁻¹. These figures are obtained by timing the full ray‑shooting pipeline—including data transfer, kernel launch, and result retrieval—over many billions of ray‑lens interactions. The authors compare these results with a reference CPU implementation (running on a 2.8 GHz Xeon) and find speed‑ups exceeding two orders of magnitude.
To demonstrate scientific relevance, the authors run a full‑scale microlensing simulation with one billion lenses. Using the four‑GPU Tesla node, the complete magnification map is generated in roughly 24 hours, a task that would otherwise require weeks on a conventional CPU cluster or would need a tree‑code approximation. The resulting maps resolve fine caustic structures and enable the production of high‑resolution light curves for a variety of source profiles (point source, Gaussian, limb‑darkened disks). The authors emphasize that the exact ray‑shooting approach preserves all interference effects and avoids the systematic errors introduced by hierarchical approximations.
The discussion addresses limitations and future directions. Memory capacity remains a constraint: the lens list must fit within the GPU’s global memory, which for the G80 generation caps the practical lens count at a few hundred million per device. However, newer architectures (Pascal, Volta, Ampere) offer tens of gigabytes of high‑bandwidth memory, suggesting that the method can be scaled to even larger simulations. The paper also outlines possible extensions, such as dynamic lens populations (moving stars), multi‑wavelength ray‑shooting, and coupling the GPU kernel with a CPU‑based tree code to handle extremely large lens ensembles while retaining exactness for the nearest lenses.
In summary, the work demonstrates that modern GPUs can accelerate the most direct and accurate gravitational lensing calculation to teraflop‑scale performance, making billion‑lens microlensing simulations feasible on a single workstation. This breakthrough opens the door to systematic, high‑precision studies of microlensing events, caustic networks, and the statistical properties of lens populations without resorting to approximations that could bias astrophysical inferences.
Comments & Academic Discussion
Loading comments...
Leave a Comment