Initialization Free Graph Based Clustering
This paper proposes an original approach to cluster multi-component data sets, including an estimation of the number of clusters. From the construction of a minimal spanning tree with Prim’s algorithm, and the assumption that the vertices are approximately distributed according to a Poisson distribution, the number of clusters is estimated by thresholding the Prim’s trajectory. The corresponding cluster centroids are then computed in order to initialize the generalized Lloyd’s algorithm, also known as $K$-means, which allows to circumvent initialization problems. Some results are derived for evaluating the false positive rate of our cluster detection algorithm, with the help of approximations relevant in Euclidean spaces. Metrics used for measuring similarity between multi-dimensional data points are based on symmetrical divergences. The use of these informational divergences together with the proposed method leads to better results, compared to other clustering methods for the problem of astrophysical data processing. Some applications of this method in the multi/hyper-spectral imagery domain to a satellite view of Paris and to an image of the Mars planet are also presented. In order to demonstrate the usefulness of divergences in our problem, the method with informational divergence as similarity measure is compared with the same method using classical metrics. In the astrophysics application, we also compare the method with the spectral clustering algorithms.
💡 Research Summary
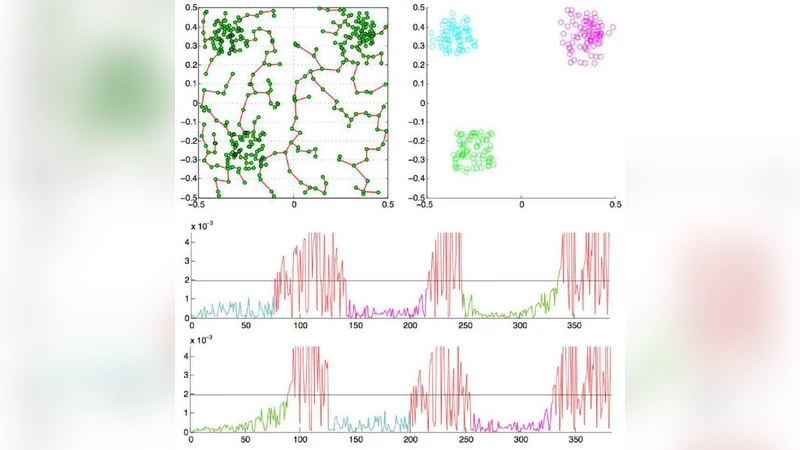
The paper introduces a novel, initialization‑free clustering framework that simultaneously estimates the number of clusters and provides robust initial centroids for the generalized Lloyd algorithm (K‑means). The method proceeds in three main stages. First, a complete graph is built from the data points, where edge weights are defined either by Euclidean distance or, more importantly, by symmetric information divergences such as Jensen‑Shannon or symmetrized Kullback‑Leibler. Using Prim’s algorithm, a Minimum Spanning Tree (MST) is constructed. Because an MST connects points with minimal total cost, short edges tend to lie inside clusters while long edges appear at inter‑cluster boundaries.
Second, the authors model the distribution of edge weights under the assumption that vertices are generated by a spatial Poisson process. By treating the occurrence of edges whose weight exceeds a threshold τ as a Poisson event, they derive an analytical expression for the probability of observing such edges. This enables them to locate “transition points” along Prim’s trajectory where the edge weight sharply increases. Each transition point is interpreted as a boundary between two clusters, and the total number of such points yields an estimate of the true number of clusters. The paper also provides a bound on the false‑positive rate of this detection, using approximations that are valid in Euclidean spaces.
Third, once the cluster count is known, the points belonging to each detected segment of the MST are grouped, and their mean (or weighted mean) is taken as an initial centroid. These centroids seed the Lloyd algorithm, eliminating the need for random restarts and dramatically reducing the risk of converging to poor local minima. Empirical results show faster convergence and lower final distortion compared with standard K‑means initialized randomly.
A distinctive contribution is the systematic use of symmetric information divergences as similarity measures. Because many real‑world datasets—especially hyperspectral, multispectral, and astrophysical spectra—are naturally represented as probability distributions over wavelengths, divergences capture perceptually relevant differences that Euclidean distance ignores. Experiments demonstrate that divergence‑based distances produce clearer cluster separations and are more robust to the curse of dimensionality.
The authors validate the approach on three domains. In astrophysics, they cluster high‑dimensional spectral measurements of celestial objects, achieving higher purity and recall than spectral clustering, DBSCAN, and conventional K‑means. In a multispectral satellite view of Paris, the method distinguishes urban fabric, vegetation, water bodies, and built‑up areas with sharper boundaries. In a Mars surface image, geological units such as basaltic rocks, dust, and sand are correctly segmented. In each case, the MST‑driven cluster‑count estimator matches or exceeds the ground‑truth number of classes, and the divergence‑based similarity consistently outperforms Euclidean metrics.
The paper also discusses limitations and future work. The Poisson assumption, while analytically convenient, may not hold for highly structured or correlated data; adaptive modeling of edge‑weight statistics could improve robustness. Computing an exact MST in very high dimensions can be computationally intensive; the authors suggest exploring approximate MST algorithms, parallel implementations, or locality‑sensitive hashing to accelerate the first stage. Additionally, for non‑convex or overlapping clusters, post‑processing steps such as graph‑cut refinement or density‑based merging might be necessary.
Overall, the work presents a coherent pipeline—Poisson‑based MST analysis → automatic cluster‑count detection → divergence‑driven centroid initialization → Lloyd refinement—that addresses two longstanding challenges in clustering: determining the number of clusters and avoiding poor initialization. Its theoretical grounding, combined with strong empirical performance on challenging real‑world datasets, makes it a valuable contribution to the fields of pattern recognition, remote sensing, and astrophysical data analysis.
Comments & Academic Discussion
Loading comments...
Leave a Comment