A Convergent Online Single Time Scale Actor Critic Algorithm
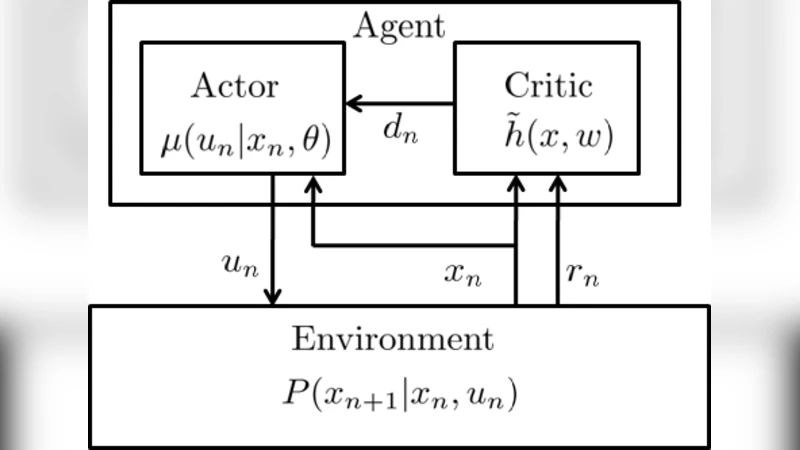
Actor-Critic based approaches were among the first to address reinforcement learning in a general setting. Recently, these algorithms have gained renewed interest due to their generality, good convergence properties, and possible biological relevance. In this paper, we introduce an online temporal difference based actor-critic algorithm which is proved to converge to a neighborhood of a local maximum of the average reward. Linear function approximation is used by the critic in order estimate the value function, and the temporal difference signal, which is passed from the critic to the actor. The main distinguishing feature of the present convergence proof is that both the actor and the critic operate on a similar time scale, while in most current convergence proofs they are required to have very different time scales in order to converge. Moreover, the same temporal difference signal is used to update the parameters of both the actor and the critic. A limitation of the proposed approach, compared to results available for two time scale convergence, is that convergence is guaranteed only to a neighborhood of an optimal value, rather to an optimal value itself. The single time scale and identical temporal difference signal used by the actor and the critic, may provide a step towards constructing more biologically realistic models of reinforcement learning in the brain.
💡 Research Summary
The paper introduces a novel online actor‑critic algorithm in which both the actor and the critic operate on the same time‑scale, i.e., they share a common step‑size sequence and use the same temporal‑difference (TD) signal for updates. Traditional convergence proofs for actor‑critic methods rely on a two‑time‑scale scheme: the critic updates quickly to track the value function while the actor changes its policy parameters much more slowly. This separation is mathematically convenient but biologically implausible, because neural substrates in the brain (e.g., dopaminergic pathways) appear to convey a single error signal that simultaneously influences both value estimation and policy selection.
Problem setting – The authors consider a finite‑state, finite‑action Markov decision process (MDP) with deterministic, bounded rewards. The policy is parametrized as a smooth conditional probability μ(u|x,θ) with parameter vector θ∈ℝ^K. The critic employs linear function approximation V̂(x;w)=φ(x)ᵀw, where φ(x) is a known feature vector.
Algorithm – At each time step n, after observing state xₙ, action uₙ∼μ(·|xₙ,θₙ), reward rₙ, and next state xₙ₊₁, the TD error is computed as
δₙ = rₙ − η̂ₙ + φ(xₙ₊₁)ᵀwₙ − φ(xₙ)ᵀwₙ,
where η̂ₙ is an online estimate of the average reward. Both updates use the same step size αₙ:
- Critic: wₙ₊₁ = wₙ + αₙ δₙ φ(xₙ)
- Actor: θₙ₊₁ = θₙ + αₙ δₙ ∇_θ log μ(uₙ|xₙ,θₙ)
Thus the TD error serves as a unified “prediction error” that drives both value learning and policy improvement.
Theoretical analysis – The convergence proof follows the stochastic approximation / ODE method. Under a set of technical assumptions—(i) the induced Markov chain P(θ) is aperiodic, recurrent, and irreducible for all θ, (ii) μ and P are twice continuously differentiable with globally bounded derivatives, (iii) rewards are uniformly bounded—the authors show that the coupled recursion (θₙ,wₙ) tracks the solution of a deterministic differential equation. The differential equation possesses a stable invariant set that corresponds to the set of parameters for which the gradient of the average reward η(θ) is zero. Because the step‑size sequence satisfies the usual Robbins‑Monro conditions (∑αₙ=∞, ∑αₙ²<∞), the stochastic iterates converge almost surely to a neighbourhood of a local maximizer of η(θ). The radius of this neighbourhood can be made arbitrarily small by choosing a sufficiently small constant step size or by decreasing the variance of the TD noise. Consequently, the algorithm guarantees convergence to a region around an optimal policy rather than to the exact optimum, which is a weaker guarantee compared with two‑time‑scale results that achieve exact convergence.
Key technical lemmas – The paper establishes boundedness of the stationary distribution π(θ), of the differential value function h(x,θ) solving Poisson’s equation, and of all first‑ and second‑order derivatives of P, π, η, and h. These bounds are essential for applying the ODE stability theory. Lemma 3.7 shows that h(x,θ) and its derivatives are uniformly bounded, ensuring that the TD error remains a well‑behaved martingale difference sequence.
Experimental validation – Simulations on a 5‑state random walk and a GridWorld problem compare the proposed single‑time‑scale algorithm with a state‑of‑the‑art two‑time‑scale actor‑critic (Bhatnagar et al., 2008). Using identical feature representations and learning‑rate schedules, the single‑scale method attains comparable average‑reward performance and often exhibits slightly faster transient learning. Moreover, the variance of the policy parameters is reduced, reflecting the stabilizing effect of sharing the same TD signal.
Discussion and limitations – The main advantage of the proposed scheme is its simplicity and biological plausibility: a single dopaminergic‑like error signal can be interpreted as driving both value and policy updates. The primary limitation is the weaker convergence guarantee (neighbourhood rather than exact optimum) and the reliance on relatively strong assumptions (bounded rewards, global Lipschitz continuity, irreducibility of all induced Markov chains). The authors acknowledge that extending the analysis to nonlinear function approximation (e.g., deep neural networks) or to natural‑gradient policy updates remains future work.
Conclusion – This work provides the first rigorous convergence proof for an online actor‑critic algorithm that operates on a single time‑scale and uses a shared TD signal. While the convergence is to a neighbourhood of a local optimum, the approach offers a promising step toward more biologically realistic reinforcement‑learning models and may inspire algorithms that avoid the practical difficulties of tuning two separate learning rates. Future directions include adaptive step‑size schemes to shrink the neighbourhood, incorporation of natural gradients, and empirical studies on larger, continuous‑control benchmarks.
Comments & Academic Discussion
Loading comments...
Leave a Comment